[LG Aimers] 3-1. Intruduction to Machine Learning
[공지사항] [해당 내용은 LG에서 주관하는 LG Amiers : AI 전문가 과정 4기 교육 과정입니다.] 강의를 듣고 이해한 내용을 바탕으로 직접 필기한 내용입니다. LG AI
3-1. Machine Learning 개론
- 교수
- 서울대학교 김건희
- 학습목표
- 본 모듈은 Machine Learning의 기본 개념에 대한 학습 과정입니다. ML이란 무엇인지, Overfitting과 Underfitting의 개념, 최근 많은 관심을 받고 있는 초거대 언어모델에 대해 학습하게 됩니다.
CHAPTER 1. Introduction to Machine Learning
what is Machine Learning?
- Machine Learning
- 기계학습은 인공지능의 한 분야이며, 실험적으로 얻은 Data로부터 점점 개선되도록 하는 알고리즘을 설계, 개발 하는 분야이다.
- 인공지능은 사람의 손으로 사람과 같은 지능을 만들겠다는 분야이다.
- 기계학습 뿐만이 아니라 컴퓨터 비전, 자연어 처리, 로보틱스 등의 분야를 포함하고 있다.
- Deep Learning
- 기계학습중의 신경망, 신경망중에 layer(계층)이 많은 신경망을 쓰는 특별한 분야이다.
- Deep learning도 기계학습의 분야이며 단지 어떤 특정 모델을 사용하는 기계학습의 분야이다.
- 기계 학습의 정의 (톰 미첼 교수)
- 어떤 작업 T에 대해서 경험 Data E를 기반으로 해서 어떤 특정 Performance Matrix P를 개선하는 것이다.
- Examples (체스 기계학습 알고리즘)
- T : 체스를 플레이 하는것
- P : 체스의 승률
- E : 한판 한판 둔 경험

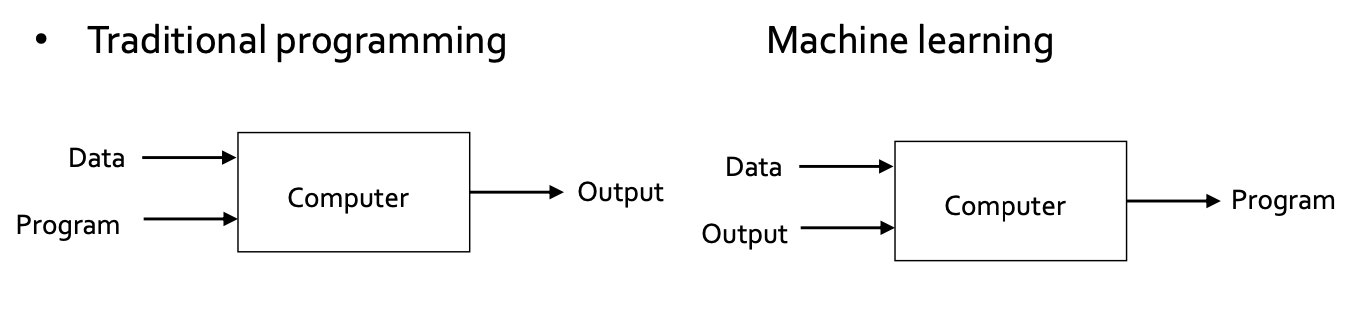
Traditional Programming VS Machine Learning
- Traditional Programming
- 전통적인 프로그래밍의 경우 코드와 Input 정보를 컴퓨터에 주면 컴퓨터가 프로그램에 정의된 순서대로 연산을 수행하고 결과값 Output을 내놓는다.
- Machine learning
- 기계학습의 경우 input과 원하는 output을 주면 최종적으로 프로그램이 나온다.
- Spell cheker프로그램의 예를 살펴보자.
- 전통적인 방식으로 spell checking 프로그램을 짜면 수많은 룰과 예외 사항이 많기 때문에 매우 어렵다.
하지만 기계학습 방식으로 한다면?
- 이런 Input이 들어가면 이런 Ouput이 나왔으면 좋겠다 라는 쌍을 최대한 많이 모와서 그것들을 학습 Data로해서 알고리즘으로 준다.
- 그럼 알고리즘으로 학습된 프로그램이 나오고 그 프로그램을 사용하는 것이다.
Generalization(일반화)
- 기계학습의 가장 큰 목표는 일반화이다.
- 만약 기계학습 알고리즘이 100개에 대해서는 Spell cheking이 가능하지만 여기에서 조금만 달라도 Spell cheking 이 불가능 하다면 일반화 능력이 전혀 없는 것이다. 100개를 Database에 넣어두고 하는 것과 다를게 없기 때문이다.
- 100개에 대한 특정 패턴을 배워 100개에 없는 Example에 대해서도 Spell checking을 하게 하는 것이 기계학습의 가장 중요한 목표이다.
No Free Lunch Theorem for ML
- 기계 학습에서 항상 명심해야 할 것 중 하나이다.
- 어떤 기계학습 알고리즘도 다른 기계학습 알고리즘 보다 항상 좋다고는 할 수 없다는 것이다.
- 즉, 모든 가능한 문제에 대해 최적으로 작동하는 보편적인 알고리즘이 없다는 것이다.
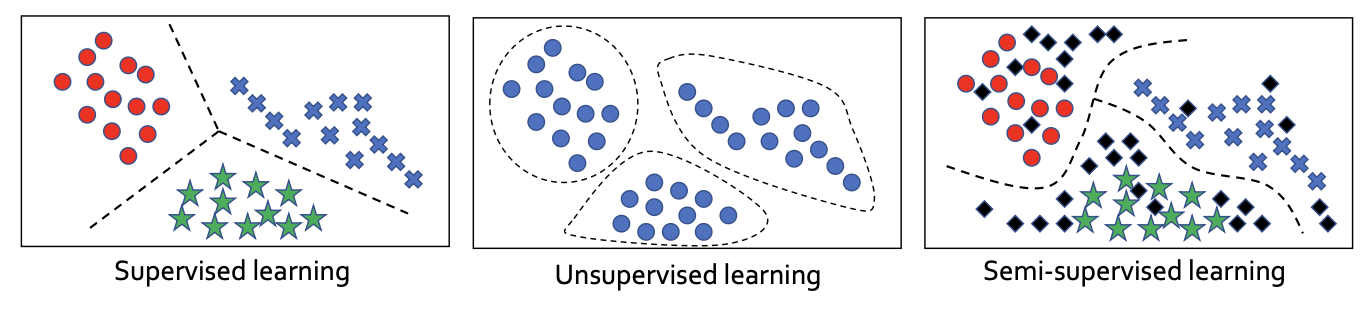
Types of Learning
- Supervised learning (지도 학습)
훈련 데이터에는 원하는 출력이 포함돼 있다,
- Unsupervised learning (비지도 학습)
훈련 데이터에는 원하는 출력이 포함되어 있지 않다.
- Semi-supervised learning (준지도 학습)
훈련 데이터 중 일부에는 원하는 출력이 포함돼 있다.
- Reinforcement learning (강화 학습)
고정된 데이터셋이 아니라 환경이 있다.
일련의 행동에서 얻는 보상이 있다
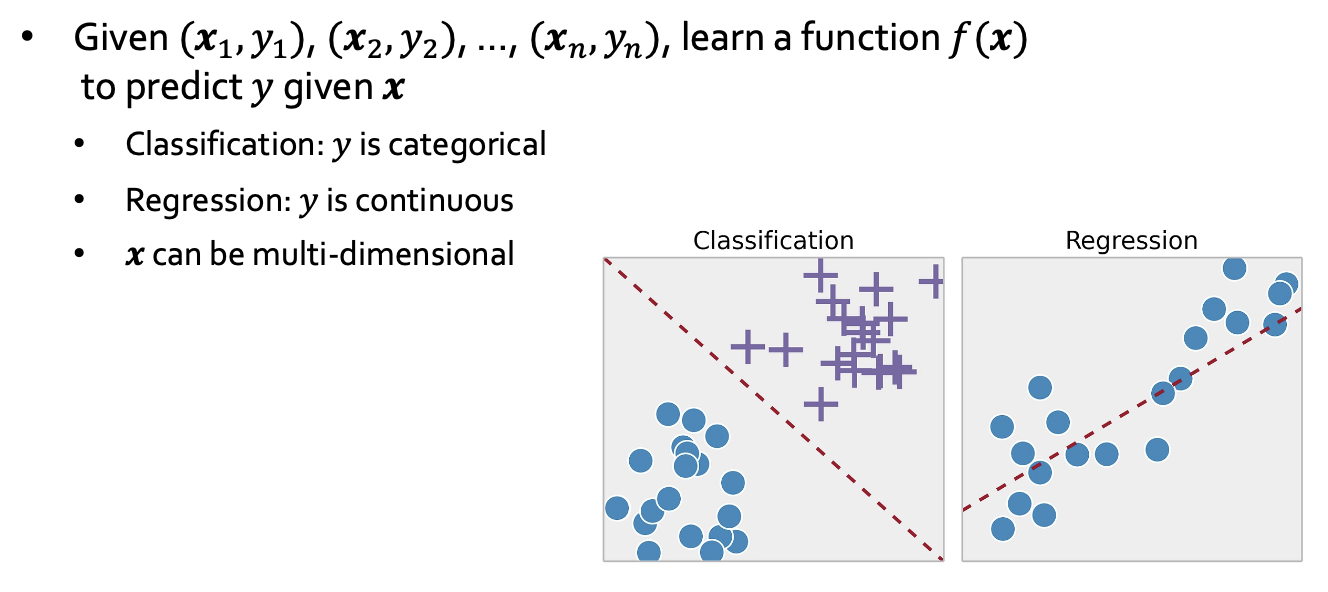
1. Supervised Learning(지도학습)
-
학습 Data가 X,Y 쌍(Input, Output) 으로 구성 되어있다.
-
X1이 들어가면 Y1, Xn이 들어가면 Yn 이 나와야 된다고 알려주는 것이다.
- Classfication (분류)
- Output이 범주형 변수 인 것이다.
- 예를 들면 Binary Classfication라면 Positive Class, Negative Class 로 나뉠 수 있다.
- Regression (회귀)
-
Output이 실수로 예측 된다.
-
많은 경우에 x가 Vector를 이루게 된다. 여러 차원의 Vector가 되는 경우가 많다.
-
2. Unsupervised Learning(비지도학습)
- 학습 Data가 x로만 구성되어 있다.
- 지도학습과 달리 원하는 결과에 대해서 기대하기 어렵다.
- 가장 큰 이유는 알고리즘의 문제가 아니라 원하는 Output에 대한 정보가 없기 때문이다.
- Clustering (군집화)
- Anomaly Detection (이상치 탐색)
- Density Estimation(분포 추정)
3. Semi-supervised learning (준지도 학습)
- 지도 학습과 비지도 학습의 중간에 있다.
- 학습 데이터에 대해서 X,Y 쌍과, 몇몇 데이터들은 그냥 X만 주는 것이다.
Unlable Data를 넣어주는 것 - 많은 경우에 이 Label(y값)을 준다는 것이 주로 사람이 작업을 하게 되는데, 시간이 많이 걸리다보니껀 몇몇 Example에 대해서는 사람이 Lableing을 하고 그 외의 데이터에 대해서는 Lableling을 하지 않은 채로 준다.
- LU Learning (Labeled + Unlabeled Data):
- 일부는 알려진 상태(레이블이 붙은 데이터), 나머지는 모르는 상태(레이블이 없는 데이터).
- 알려진 데이터로 모델을 훈련하고, 알려지지 않은 데이터를 활용하여 모델을 개선합니다.
- PU Learning (Positive-Unlabeled Learning):
- 주어진 것(긍정적인 데이터)은 있지만, 다른 것에 대한 정보는 없는 상태.
- 주어진 긍정적인 데이터로 모델을 훈련하고, 나머지 데이터를 활용하여 판별력 있는 모델을 만듭니다.
- LU Learning (Labeled + Unlabeled Data):
왜 Semi-supervised learning이 도움이 될까?
 비슷한 데이터 포인트는 비슷한 레이블을 갖는 경향이 있다. 레이블이 없는 데이터는 경계를 더 정확하게 식별하는 데 도움이 될 수 있다.
비슷한 데이터 포인트는 비슷한 레이블을 갖는 경향이 있다. 레이블이 없는 데이터는 경계를 더 정확하게 식별하는 데 도움이 될 수 있다.
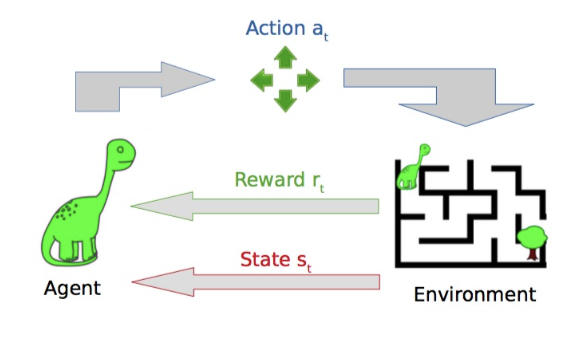
4. Reinforcement learning (강화 학습)
에이전트(agent)가 환경과 상호작용하면서 특정 작업을 수행하는 방법을 학습하는 기계학습의 한 분야이다. 에이전트는 환경에서 보상을 최대화하는 방향으로 행동을 선택하고 학습한다.
- 고정된 데이터셋이 아니다.
- 새로운 데이터를 계속해서 받아들이고 학습한다.
- 감독자 대신 보상
- 감독자가 없지만 올바른 행동에 대해 보상을 받아 학습한다.
- 피드백이 지연될 수 있다.
- 피드백은 즉각적이지 않고 지연될 수 있습니다.
- 에이전트의 행동이 이후 데이터에 영향을 준다.
- 시스템의 행동은 그 다음 데이터에 영향을 줄 수 있다.
댓글남기기