[LG Aimers] 3-2. Intruduction to Machine Learning
[공지사항] [해당 내용은 LG에서 주관하는 LG Amiers : AI 전문가 과정 4기 교육 과정입니다.] 강의를 듣고 이해한 내용을 바탕으로 직접 필기한 내용입니다. LG AI
3-2. Machine Learning 개론
- 교수
- 서울대학교 김건희
- 학습목표
- 본 모듈은 Machine Learning의 기본 개념에 대한 학습 과정입니다. ML이란 무엇인지, Overfitting과 Underfitting의 개념, 최근 많은 관심을 받고 있는 초거대 언어모델에 대해 학습하게 됩니다.
CHAPTER 2. Bias and Variance
Generalization
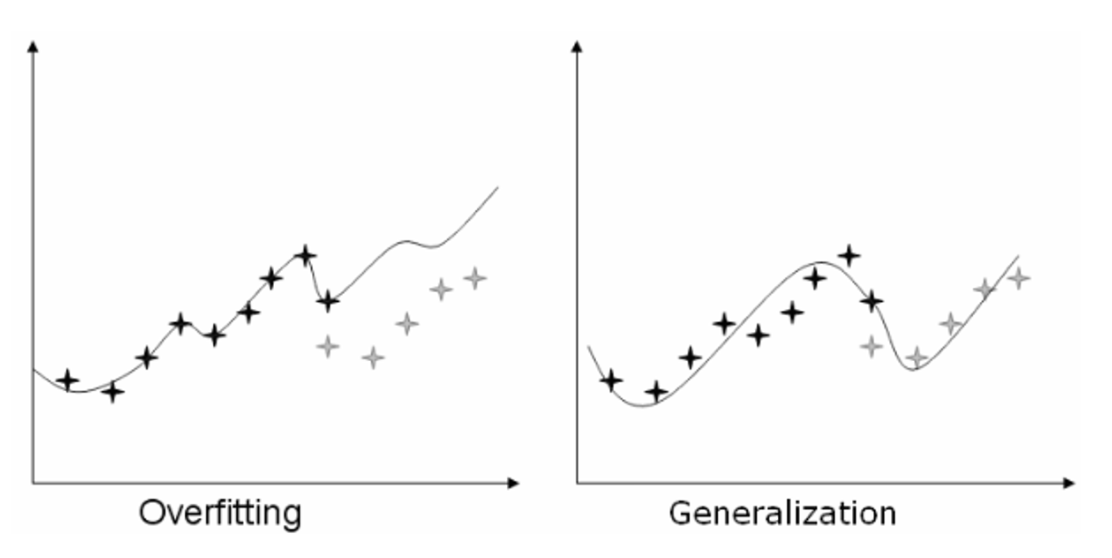
- 일반화란 기계학습의 능력이다.
- 기계학습이 학습한 데이터보다 새로운 데이터에 대해서 잘 하는 것이 중요하다. → 일종의 모순이다.
- 일반화 능력은 Overfitting(과적합)과 개념이 밀접하다.
- 검정색 별 부분을 학습 Data라고 할 때
- 왼쪽 그림의 경우 복잡한 함수로 구성되어 있으며 새로운 데이터에 대한 영역이 Up,down이 심하다.
- 오른쪽 그림의 경우 학습된 부분들이 부드럽기 때문에 새로운 영역에 대해서도 잘본다.
- 따라서 실제 Y값과 함수 값의 Training Error 가 큼에도 불구하고 이 함수를 활용한다.
Training Data vs Test Data
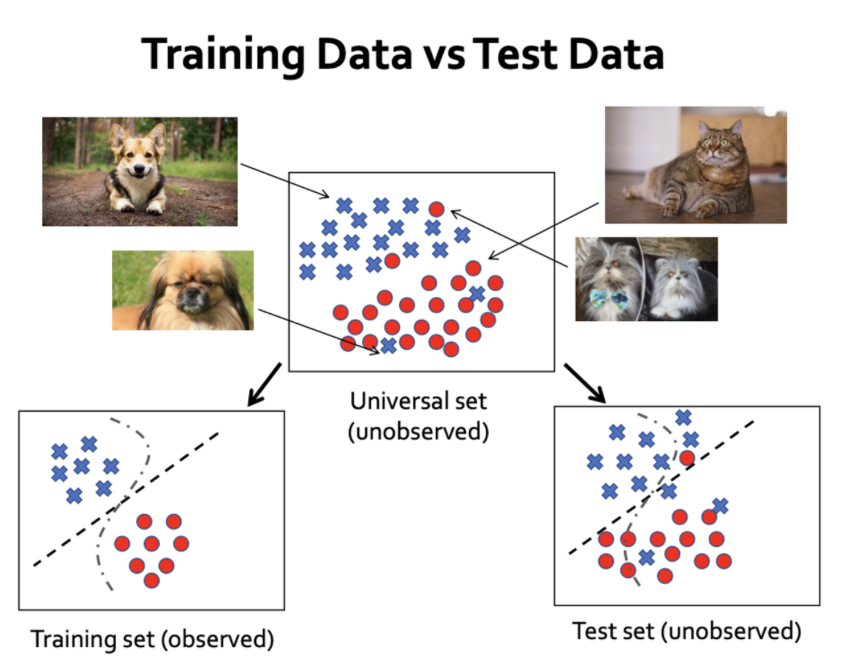
- Universal Set (전체 집합):
- Universal Set은 일반적으로 데이터셋이나 분석 대상의 전체 집합을 나타낸다.
- Training Set (훈련 집합):
- Training Set은 기계 학습 모델을 훈련시키기 위한 Universal Set의 Samling이다. 이것은 입력-출력(이사진은→고양이) 쌍으로 이루어져 있으며, 모델은 입력과 출력 간의 패턴과 관계를 학습한다.
- Test Set (시험 집합):
- Test Set은 Training Set과 별도로 유지되는 Universal Set의 또 다른 부분이다. 모델 훈련 후에는 모델을 테스트 세트에서 평가하여 새로운, 보지 못한 데이터에 대한 성능을 평가하고 일반화 능력을 추정한다.
Generalization Error
-
Loss를 하나의 숫자로 요약한다. Loss는 확률 분포를 따르는데 모델이 예측한 값과 실제 정답 간의 차이를 측정하여 모델의 성능을 평가하는 것이다.
-
Generalization Error(일반화 오차) 를 구하는 이 수식을 보면 예측값 h(x), y에 대한 Loss를 E라는 숫자로 표현한다.
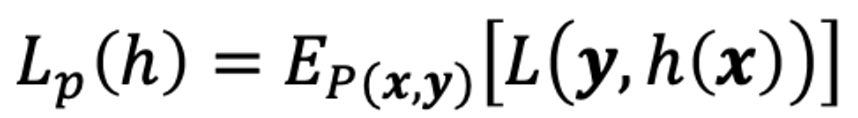
- 과소적합 (Underfitting):
- 일반화 오차 < 훈련 오차.
- 과적합 (Overfitting):
- 일반화 오차 > 훈련 오차.
- 일반적으로 과소적합이 최악의 경우이다. “학습도 제대로 못 시켰네” 라는 기계학습의 기본조차도 못한것처럼 이야기 하는 경우가 많다. 따라서 우선적으로 과적합을 목표로 기계학습을 하면 된다.
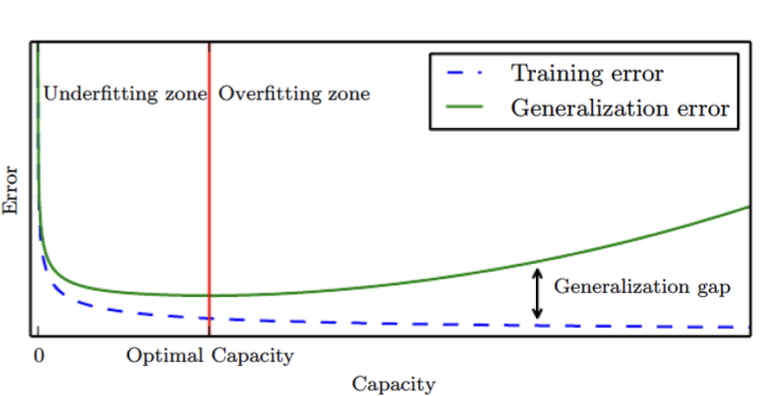
Model’s Capacity
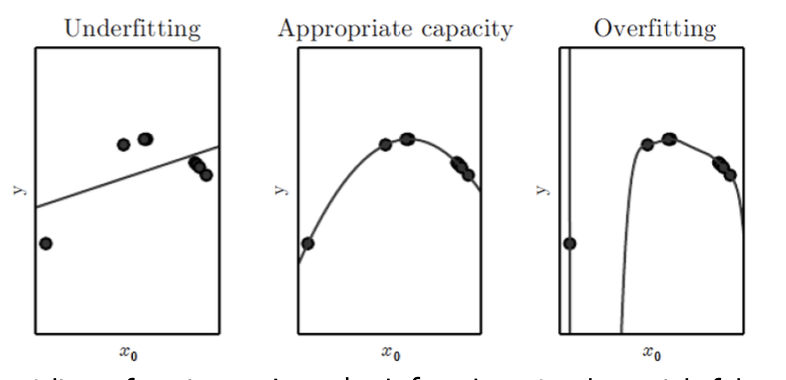
- 다음과 같이 7개의 데이터를 fit 한다고 가정해보자.
- 선형함수 , 2차함수, 9차 함수 순으로 fitting을 한다고 가정한다면.
- 선형함수
- 데이터의 굴곡이 있을때 선형함수를 사용한다면 과소적합이 날 수 밖에 없다. Training Error를 줄일 수 가 없다.
- 9차함수
- 복잡한 함수를 쓰면 Training Error 는 무조건 작아진다. 즉 Capacity가 늘어날 수록 무조건 작아진다.
- 하지만 너무 복잡한 모델을 쓰면 데이터가 없는 부분의 굴곡이 엄청나게 심하다. 따라서 과적합이 일어날 수 있다.
- Training Error 는 복잡도를 높이면 높을수록 줄어든다.
- 하지만 기계학습의 목적은 Training Error를 줄이는게 아니라 일반화 Error를 최소화하는 것이다.
- 따라서 파란색 보다는 녹색 그래프가 최소가 되는 지점을 찾아야한다.
- Traning Error는 학습과정에서 쉽게 볼 수 있지만 일반화 Error는 쉽게 볼 수 없다.
- ** 따라서 Cross Validation등의 테크닉을 써서 일반화 Error를 예측한다.**
- Traning Error는 학습과정에서 쉽게 볼 수 있지만 일반화 Error는 쉽게 볼 수 없다.
규제화 (Regularization)
-
Bias/Variance Decomposition (편향/분산 분해)
-
편향은 모델이 실제 값과 얼마나 떨어져 있는지를 나타낸다. 낮은 편향은 모델이 데이터를 잘 예측한다는 것을 의미한다.
-
분산은 데이터를 다르게 샘플링할 때 모델이 얼마나 변하는지를 나타낸다. 낮은 분산은 모델이 안정적이라는 것을 의미한다.
-
-
Trade-off between Bias and Variance (편향과 분산 간의 균형)
-
모델 복잡도를 늘리면 분산은 증가하고 편향은 감소하는 경향이 있다.
-
즉, 모델이 데이터에 더 잘 적합되지만, 과적합의 위험이 있다.
-
둘 다 낮을 수록 좋기 때문에 이 둘의 균형이 중요하다.
-
-
Overfitting vs Underfitting (과적합 대 과소적합)
-
높은 분산은 모델이 데이터에 과하게 적합되어 새로운 데이터에 대한 일반화 성능이 떨어지는 과적합을 나타낸다.
-
높은 편향은 모델이 데이터에 부적합하여 훈련 데이터에서도 성능이 낮은 과소적합을 나타낸다.
-
-
Weight decay(가중치 감쇠)
- 가중치 감쇠는 모델이 너무 복잡하지 않게 유지하면서도 중요한 특징을 학습하도록 도와주는 규제화 방법이다. 이를 통해 모델의 일반화 성능을 향상시킬 수 있다.
CHAPTER 3. Recent Progress of Large Language Models(초거대 언어모델)
GPT 3
- Generative Pretrained Transformer (생산적인 학습된 딥러닝 아키텍쳐 Transformer)
- 과거에는 정해진 task만 수행하는 모델이 많았지만 GPT는 일반 인공지능을 다룬다.
- 언어 이해와 생성에 대한 모든 질문을 대답한다.
- 1750억 파라미터
InstructGPT
- GPT 3.5
- 언어 이해와 생성을 할 수 있는 GPT3를 가져다가 사람의 지시가 주어졌을때 유용하고 안전하게 만든 모델이다.
- Key idea : 사람의 피드백을 강화학습한다.
-
- 이런 질문이 들어오면 이렇게 해야해 라는 감독학습을 한다.
- 어느정도 응답 수준이 되면 하나의 질문에 대해서 여러 응답을 생성하게 함
- 선호하는 응답에 대한 랭킹으로 대답한다.
-
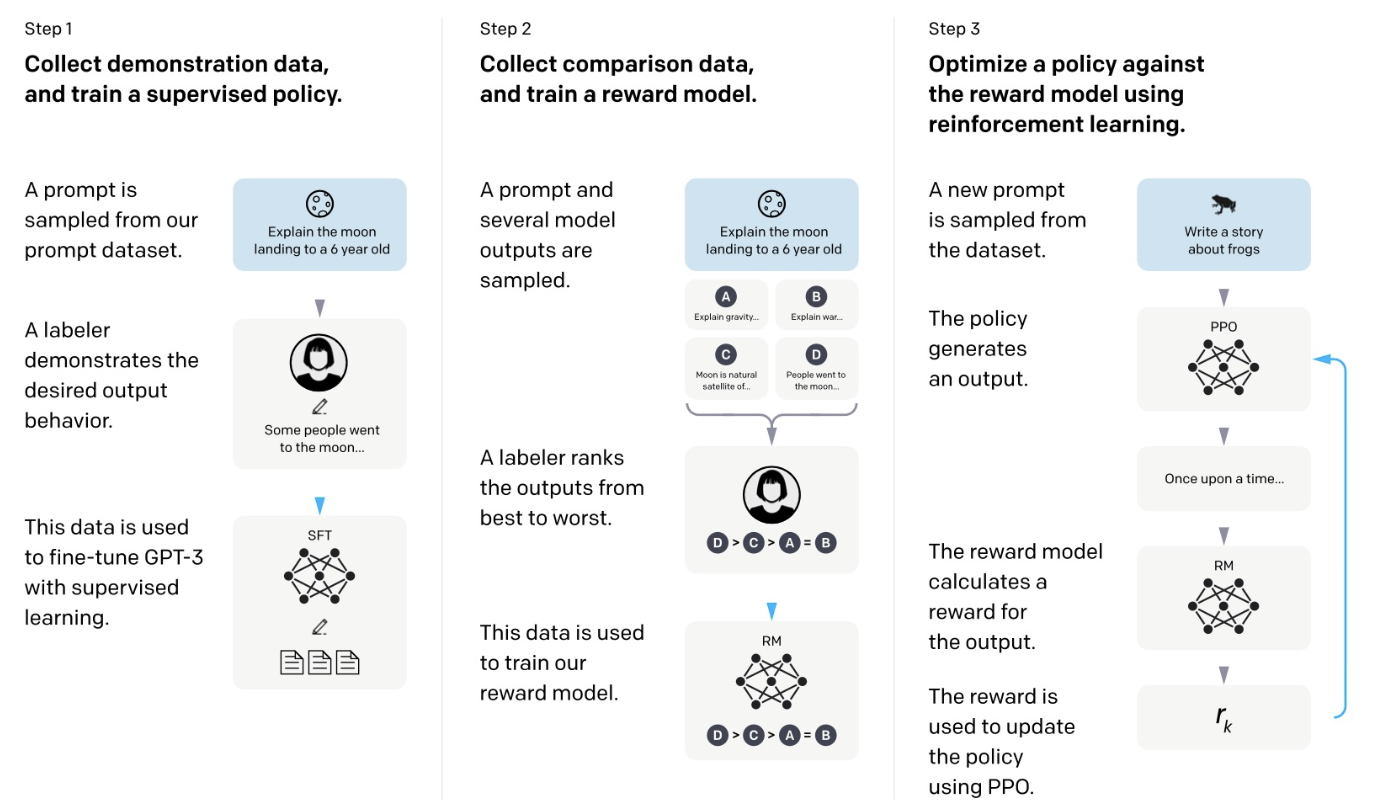
step 1: GPT-3를 감독 학습하여 사람의 지시에 따라 여러 응답을 생성하고, 각 응답에 대한 레이블을 생성한다.
Step 2: Reward Model (RM)을 학습하여 응답을 평가하는 선호도에 따라 Ranking score를 생성한다.
Step 3: 새로운 질문에 대한 응답을 생성하고, 강화 학습에서 얻은 Ranking score를 보상으로 활용하여 모델을 향상시킨다.
Chat GPT
- API 호출을 해야하는 InstructGPT와 달리 채팅 형식으로 진핸된다.
- Iterative Deployment
- InstructGPT 와 달리 거짓말에 대한 처리가 향상 되었다.
GPT-4
-
Large multimodal language model(대규모 대중모달 언어 모델)
- 텍스트 뿐만이 아니라 어떤 정보 형식이 오더라도 이해할 수 있어야한다. GPT4 는 이미지와 텍스트에 대해서도 가능하다.
-
이제부턴 아무런 기술적 디테일을 공개하지 않는다.
-
이전 GPT 모델처럼 거짓 정보를 생성하거나 추론 오류를 일으키는 등의 문제가 여전히 존재한다.
Anthropic Claude
- Anthropic AI는 OpenAI의 전 연구원들이 창립한 회사로, ChatGPT와 유사한 작업을 수행하는 Claude라는 모델을 보유하고 있다.
- 더 예측 가능하고 해로운 결과를 적게 생성한다고 주장한다.

Google Bard
- Google은 ChatGPT에 대해 ‘Code Red’를 발표하며 Google의 검색 엔진을 일부 대체할 수 있는지에 대한 논의를 시작했다.
- Bard는 아직 공개되지 않았으며 정보가 제한적이다.
Google PaLM
- Google의 PaLM은 Google의 Pathways 시스템을 기반으로 효율적인 스케일링을 제공한다.
- 다양한 기능을 수행하며 멀티홉 추론, 코드 생성, 농담 설명 등에서 뛰어난 성능을 보인다.
Meta OPT & LLaMA
- Open Source로 공개를 해서 Userbase를 넓히는 계획.
- GPT3와 유사한 성능을 나타내면서도 개발에 필요한 탄소 발자국이 1/7에 불과하다.
- Stanford Alpaca:
- LLaMA 7B 모델 파인튜닝.
- GPT-3.5로 생성된 52,000개 샘플 사용.
- 작고 저렴하면서 성능이 우수.
- LMsys Vicuna:
- LLaMA 13B 모델 파인튜닝.
- 500,000개의 대화 샘플 사용.
- 약 $300 비용으로 높은 품질의 ChatGPT와 유사한 결과.
- Self-Instruct Tuning on LLaMA - GPT-4 Response Comparison:
- GPT-4에 의한 평가에서 Vicuna-Instructions-80은 여덟 가지 범주에 대해 10개의 질문을 생성하며 SoTA 프로프리어터리 챗봇과 유사한 성능을 나타냄.

OpenAI’s Superalignment
- AI 시스템의 평가 및 해석가능성을 지원하고 문제가 있는 행동을 자동으로 찾아내는 것을 목표로 한다.
결론
- 데이터 중심 AI에 대한 강조: 모델 아키텍처 및 교육 전략은 거의 동일하지만 데이터가 중요한 차별 요소이다.
- 오픈 소스 대 프로프리어터리 LLMs (Large Language Models) 비교 및 API 대 내부 LLM의 선택 등에 대한 논의가 있다.
댓글남기기