[LG Aimers] 5-2. 딥러닝 (Convolution Neural Networks)
[공지사항] [해당 내용은 LG에서 주관하는 LG Amiers : AI 전문가 과정 4기 교육 과정입니다.] 강의를 듣고 이해한 내용을 바탕으로 직접 필기한 내용입니다. LG AI
5-2. 딥러닝(Deep Learning)
- 교수 : KAIST 주재걸 교수
- 학습목표
- Neural Networks의 한 종류인 딥러닝(Deep Learning)에 대한 기본 개념과 대표적인 모형들의 학습원리를 배우게 됩니다.
- 이미지와 언어모델 학습을 위한 딥러닝 모델과 학습원리를 배우게 됩니다.
CHAPTER 3. Convolution Neural Networks and Image Classification
합성공 신경망(CNN)의 동작 원리 및 이를 통한 이미지 분류
- Fully Connected Neural Network
- 앞에서 배웠던 multi-layer perceptron의 경우 각 layer에서 입력노드와 출력 노드 모두와 특정한 가중치의 형태로 연결이 된 network이다.
- Convolution Neural Networks(CNN)
- 컴퓨터 비전 분야에서 거의 대부분 사용되는 핵심 딥러닝 기술이다.
- 이미지 분류, 자연어와 관련된 이미지 검색 문제, 자세 추정 문제, 의료 영상
- Recurrent Neural Networks(RNN)
- 시계열 분석에서 적용 될 수 있다.
How Convolution works
- 만약에 X, O 를 구분 하기 위해 어떻게 해야하나 생각해보자.
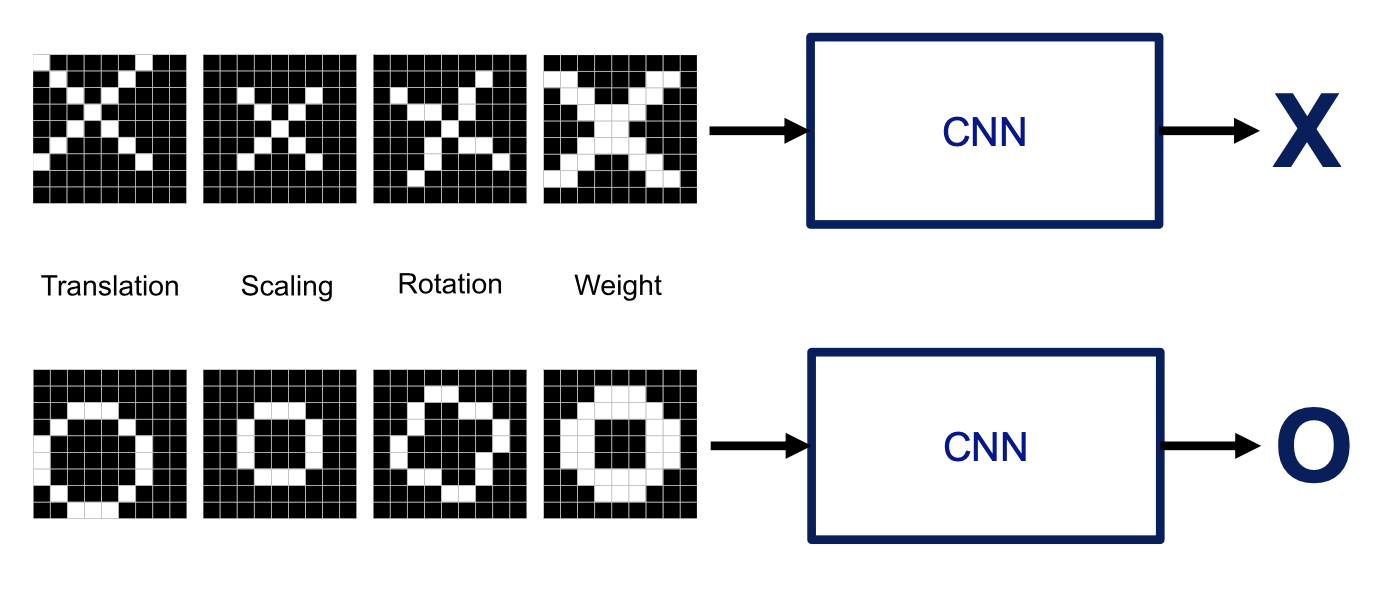
- 딥러닝이나 기타 머신러닝 알고리즘의 입력을 줄 때 하나의 숫자들로 이루어진 2차원 배열로 주게 된다.
- 하얀색 pixel 을 1로 하고 , 검정색을 0으로 한다면 다음과 같이 표시된다.

- X로 분류 하기 위해서는 픽셀이 특정한 패턴을 가지고 있는 것을 알 수 있다.
- 이에 착안해서 특정 class에 존재 할 수 있는 특정 패턴을 정의하고 패턴이 주어진 이미지에 있는지 판단하게 된다.
- 이 패턴들이 주어진 이미지 상에 어느 위치에 나타나는지 얼마나 강하게 일어났는지에 따라 구분하게 된다.
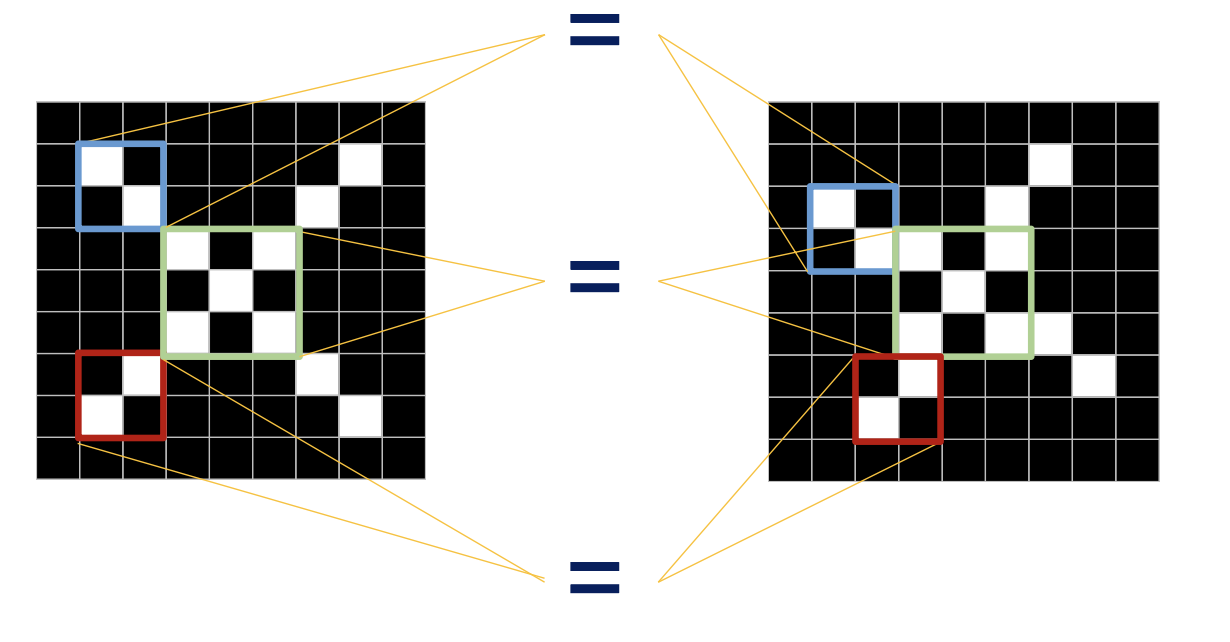
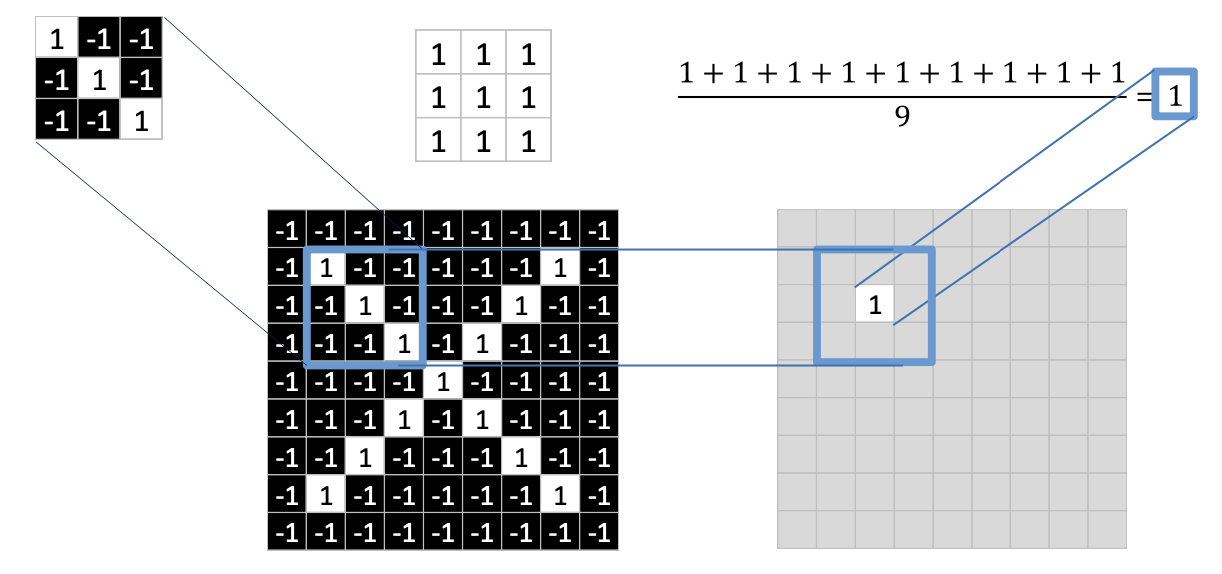
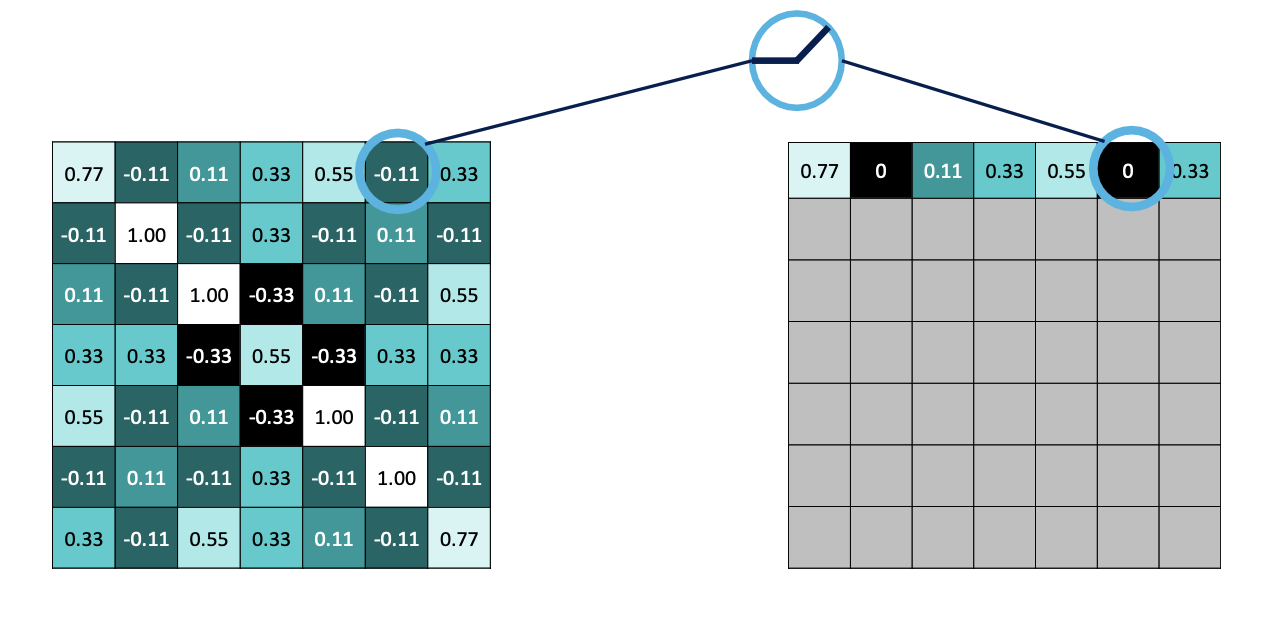
- 그렇다면 해당 패턴을 갖는지 확인 하기 위해서는 합성 곱을 통해 알 수 있다.
-
- 패턴과 같은 칸에 위치한 픽셀을 곱한다.
- 곱한 픽셀들을 모두 더한다.
- 총 픽셀의 개수만큼 나눈다.
-
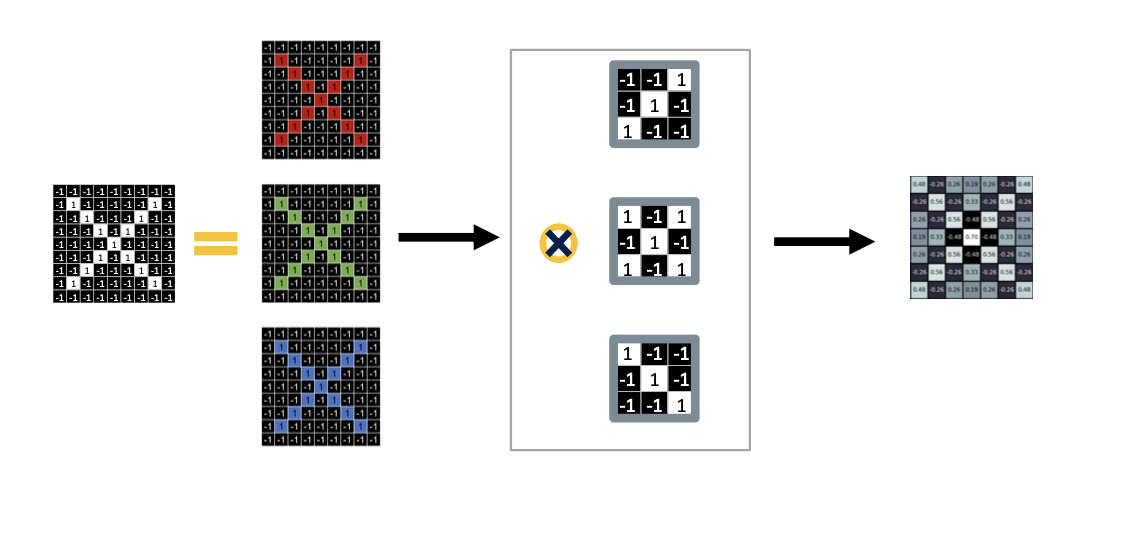
- 최종적으로 입력 이미지에 가능한 모든 위치에 오버랩 시킨다면 해당 패턴의 위치와 정도를 가지고 Activation map(활성화 지도) 를 얻을 수 있다.
- 이러한 연산을 convolution 연산이라고 한다.

Convolution Layer
- 다음 그림처럼 세 개의 채널로 이루어진 입력 이미지가 있을 때 특정한 3 by 3 필터는 각 입력 채널에 각각 대응하는 하나의 컨벌루션 필터를 이루게 된다.
- 각 채널에 대응하는 필터를 각각 컨벌루션 연산을 한 뒤에 최종적으로 모두 더하게 된다.
-
좀 더 자세한 동작 과정을 살펴보자
- 32 x 32 x 3 image (height x width x depth)에 5 x 5 x 3 필터를 씌운다면 즉, 컨벌루션 연산을 한다면
- 28 x 28 x 1 Activation map을 얻게 된다.
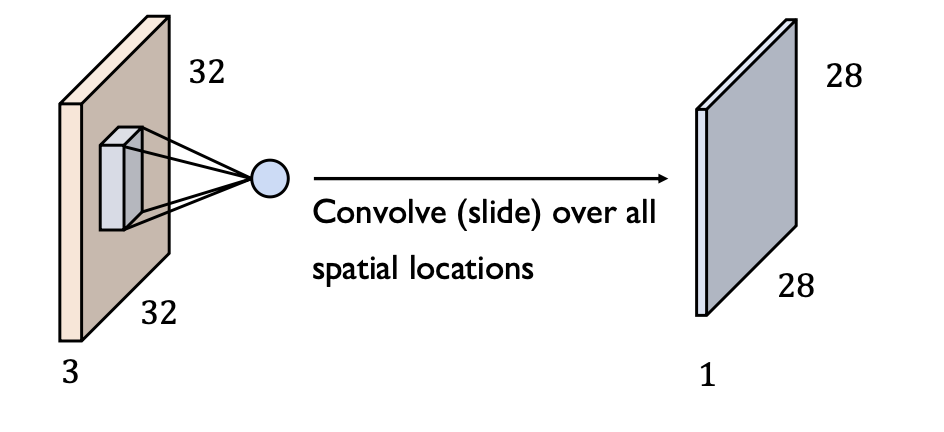
-
이 후에 다음 필터와 컨벌루션 연산을 통해 또 다른 Activation map을 얻게 된다.
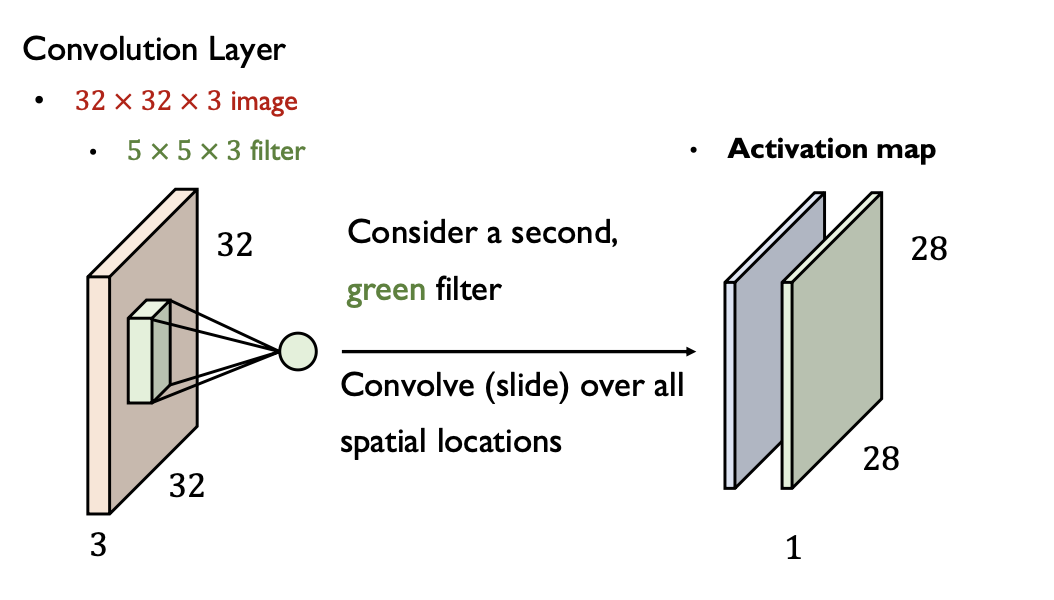
convolution filter가 3개가 있다면?
- 3채널 이미지와 filter 3개가 주어졌다면 각채널과 대응 하는 필터 3개가 컨벌루션 연산을 하게 된다.
- Activation map은 필터의 개수에 해당하는 3개가 만들어 지게 된다.
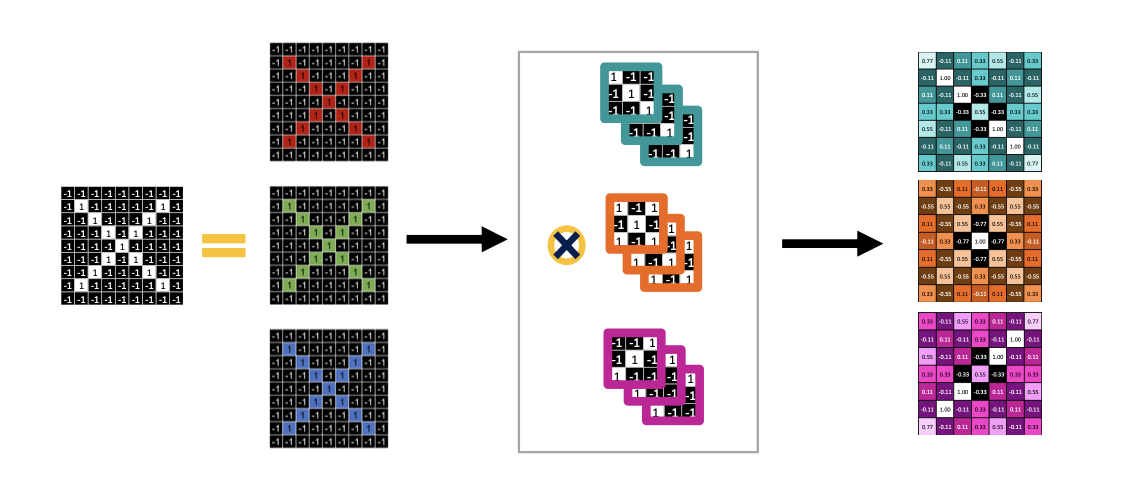
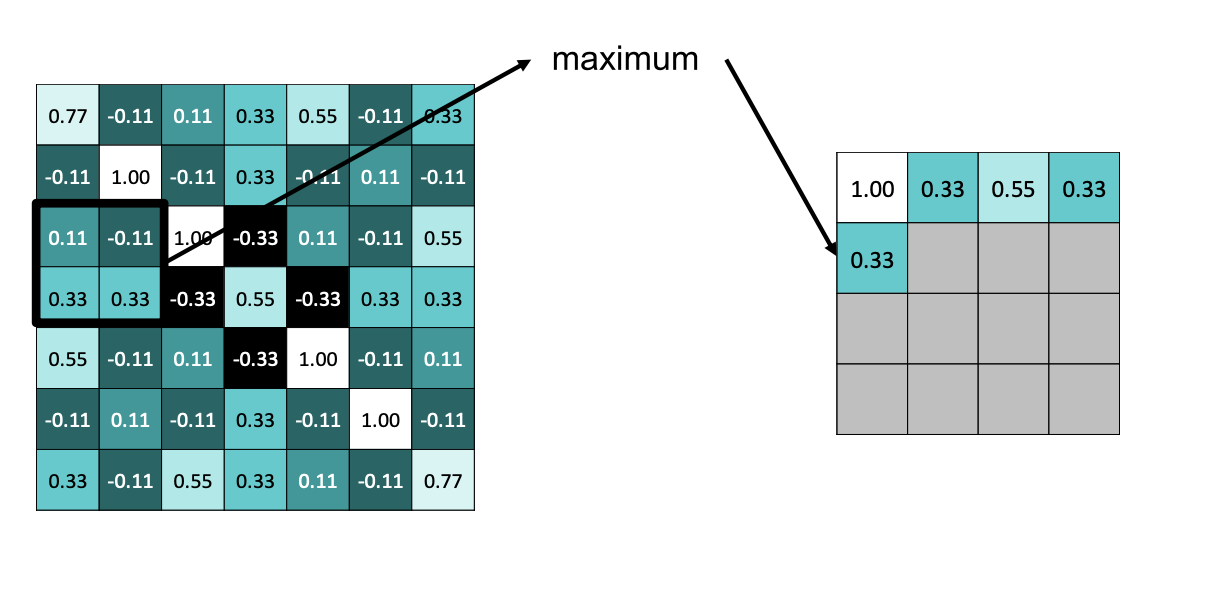
MAX Pooling
- 특정한 사이즈의 이미지 패치를 2 by 2 라고 한다면 2 by 2 에 대응하는 픽셀중 가장 큰 크기의 output 을 적게 된다.
- max pooling의 Output이미지는 2 by 2 영역에서 값을 하나만 뽑기 때문에 최종적으로 가로세로가 반으로 줄게 된다.
Rectified Linear Units (ReLUs)
- Fully Connected Neural Network 과의 유사점
- 기본적으로 convolution 연산은 앞에서 Fully Connected Neural Network 에서 봤었던 선형결합을 통해서 일어나는 연산이다. 이러한 선형 연산이후에 sigmoid, tanh, ReLU 등의 활성 함수를 통과시켜줌으로써 유연하고 다양한 패턴을 표현하게끔 만들어준다.
- ReLU 활성화 함수를 통해 양수값은 그대로 음수값은 0인 결과를 만들어 내게 된다.
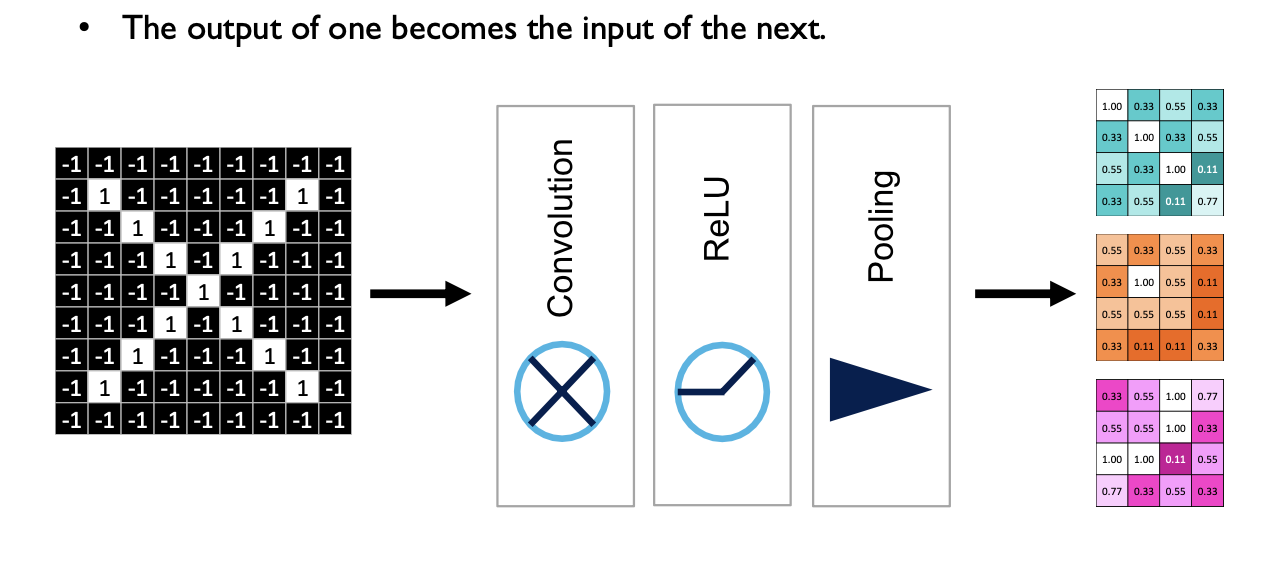
- 최종적으로 convolution 연산에서는 기본적으로 선형 결합의 가중치를 적용해서 가중합을 구하게 되는 convolution operation을 먼저 적용해주고 ReLu를 통과 한후 이미지를 조금 더 축약하도록 하는 Max pooling을 적용해 주게 된다.
- 딥러닝에서는 (컨벌루션, ReLu, Pooing) 층을 여러개 쌓는다.
Fully Connected Layer
-
Fully Connected Layer
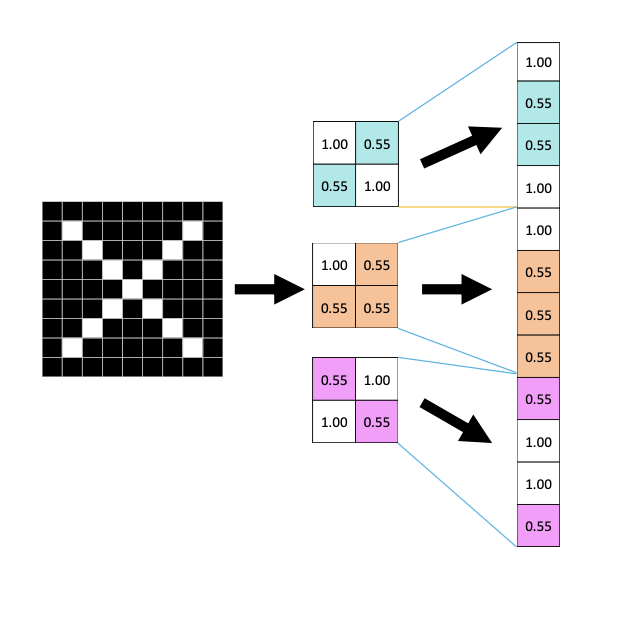
- (컨벌루션, ReLu, Pooing) 층을 반복해서 쌓게 되면 이미지 size는 최종적으로 2 by 2로 변환이된다.
- 필터를 3개를 썼기 때문에 3개의 채널로 이루어진 Output activation map을 얻게 된다.
- 이러한 Output activation map을 한줄 vector로 만들면 다음과 같이 만들어진다.
- 2x2 x 3 = 12개의 차원으로 만들어진다.
-
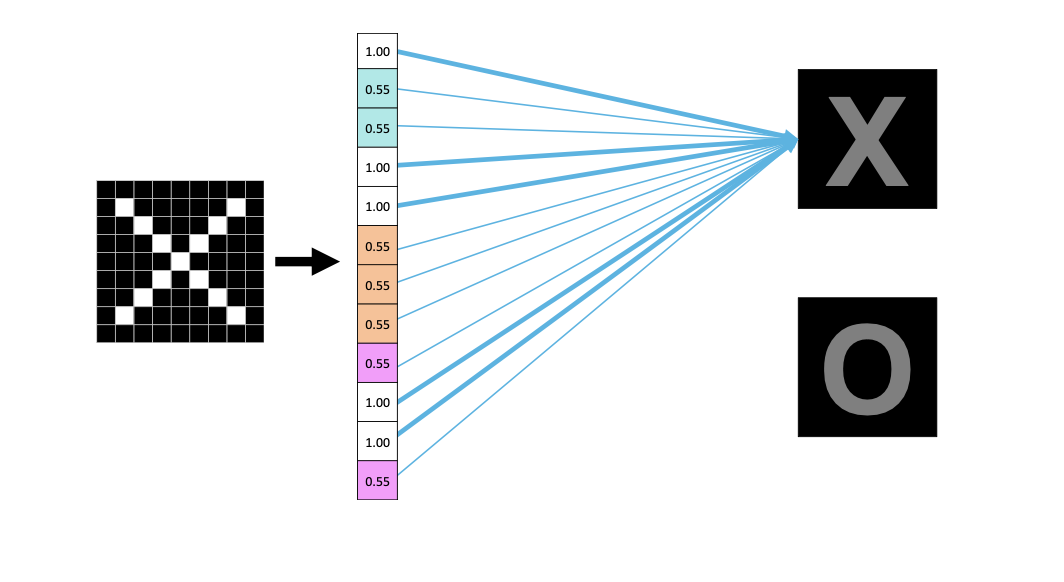
학습 과정을 통해 fully-connected layer의 가중치가 특정한 값들로 최적의 값으로 도출이 된다.
-
최종적으로 원하는 이미지를 가중치를 기반으로 계산하여 분류를 수행하게 된다.

Backpropagation
-
- 주어진 이미지가 x class에 대응한다면 1, 아니면 0이 나오게 하느 binary cross-entropy Loss나 mse 등을 써서 loss 값을 계산한다.
- gradient descent를 수행하기 위해 다시 과정을 되돌아간다.
- 파라미터들이 gradient계산을 통해 학습이 진행된다.
- 여기서 파라미터들은 컨벌루션 단계의 필터에 대한 계수를 말한다.
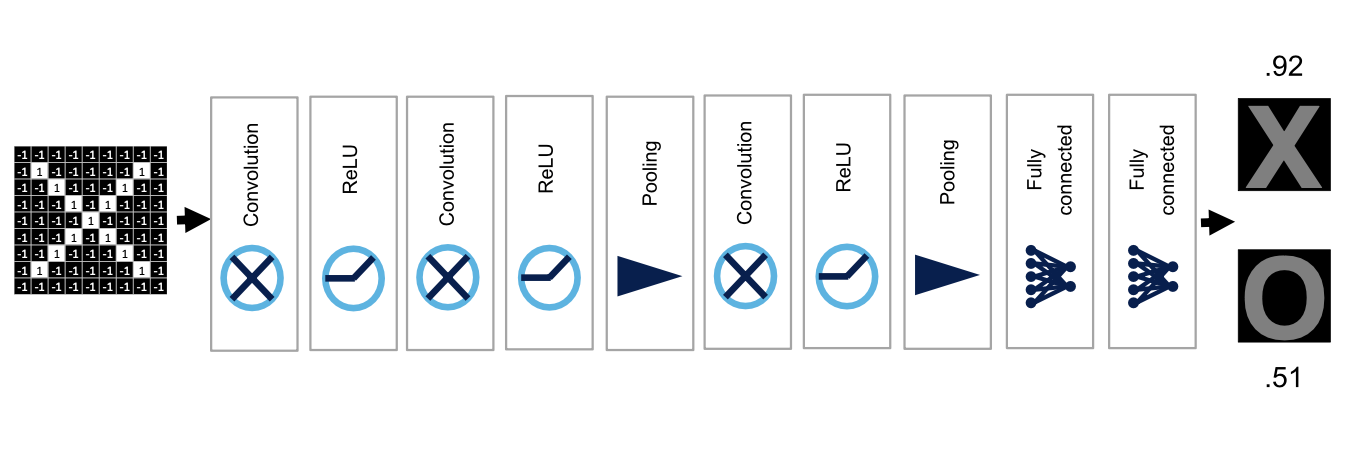
Hyperparameters
- Convolution
- 몇개의 필터를 쓸건지
- 한 필터의 가로 세로 사이즈
- Pooling
- Max pooling시 사용되는 윈도우 사이즈
- 2by2 로 하게 된다면 1/2 이 줄어들고, 3 by 3으로 하면 1/3이 줄어드는 효과가 발생한다.
- Max pooling시 이동하는 간격
- Max pooling시 사용되는 윈도우 사이즈
- Fully Connected
- layer를 몇개를 쌓을지
- 한 layer에는 몇개의 뉴런을 사용할지
Various CNN Architectures
-
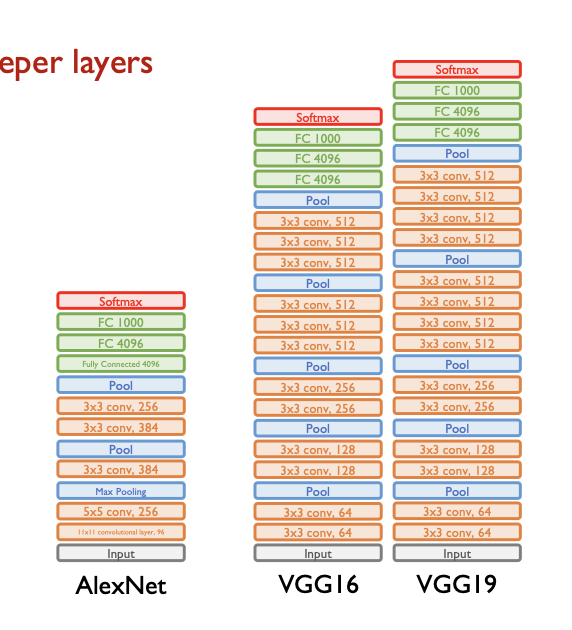
CNN에서 좋은 성능을 내는 대표적인 Architecture의 종류들은 다음과 같다.
- AlexNet
- CNN의 시초격이며 CNN 중흥기의 포문을 연 아키텍처이다.
- VGGNet
- 심플한 구조로써 layer를 잘 많이 쌓음으로써 좋은 성능을 이끌어냈다.
- GoogLeNet
- 구글의 특정한 아키텍처를 사용해서 convolution layer하나를 특정한 복잡한 형태로 만들고 그 형태를 반복적으로 사용한다.
- ResNet
- 최근 많이 사용되는 아키텍처이다.
- AlexNet
VGGNet
- 각각의 convolution layer에서 사용하는 convolution filter의 가로, 세로 size를 무조건 3 by 3으로만 한다.
- 3 by 3이라는 작은 필터에서 나오는 단점은 layer를 굉장히 깊이 쌓음으로써 커버한다.
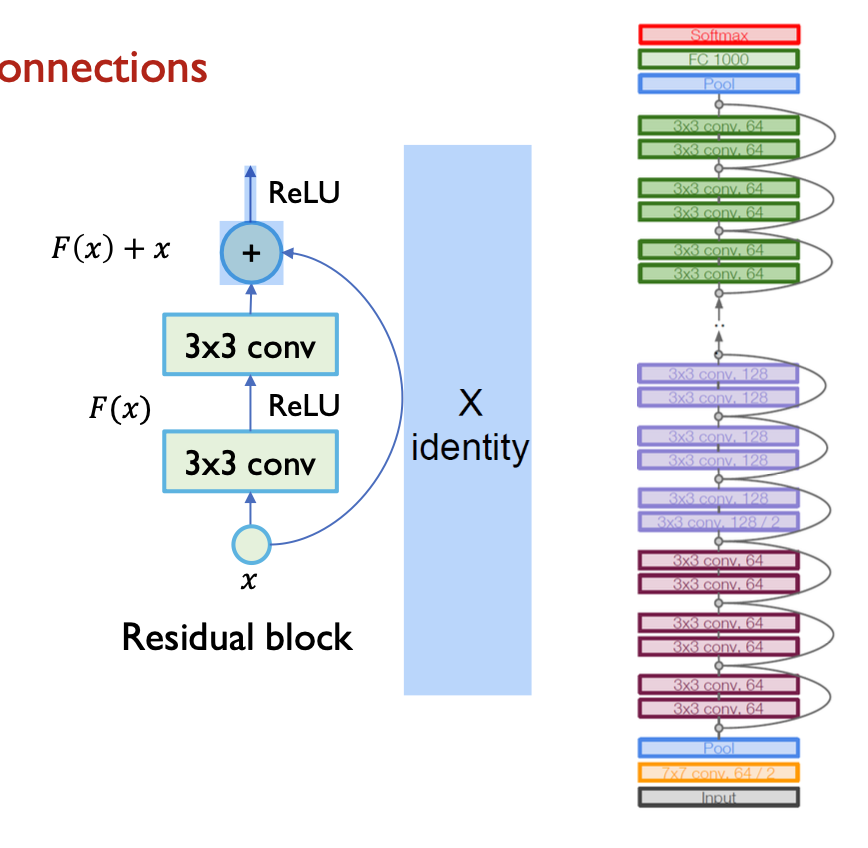
Residual Network (ResNet)
- ResNet의 핵심은 “skip connection”(잔여 연결)로, 식으로 나타내면 $H(x) = F(x) + x$
- 전체 매핑인 𝐻(𝑥)를 직접 학습하는 대신 잔여 매핑인 𝐹(𝑥)를 학습하고 입력인 𝑥를 더하는 방식을 사용한다.
- ResNet 아키텍처는 잔여 연결을 이용해 입력과 잔여 매핑을 더하는 구조로 구성된다.
- 여러 층의 합성곱과 ReLU 활성화 함수를 쌓아 깊은 신경망을 형성한다.
댓글남기기