[LG Aimers] 5-3. 딥러닝 (Seq2Seq with Attention)
[공지사항] [해당 내용은 LG에서 주관하는 LG Amiers : AI 전문가 과정 4기 교육 과정입니다.] 강의를 듣고 이해한 내용을 바탕으로 직접 필기한 내용입니다. LG AI
5-3. 딥러닝(Deep Learning)
- 교수 : KAIST 주재걸 교수
- 학습목표
- Neural Networks의 한 종류인 딥러닝(Deep Learning)에 대한 기본 개념과 대표적인 모형들의 학습원리를 배우게 됩니다.
- 이미지와 언어모델 학습을 위한 딥러닝 모델과 학습원리를 배우게 됩니다.
CHAPTER 4. Seq2Seq with Attention for Natural Language Understanding and Generation
Recurrent Neural Networks(RNN)
- RNN 은 기본적으로 sequence data에 특화된 형태를 띄게 된다.
- 이름에서 알수있다 시피 RNN이라는 동일한 function을 반복적으로 호출한다.
-
앞서 배웠던 multi-layer perceptron, fully-connected layer, CNN 과 더불어서 특정한 형태의 neural network이다.
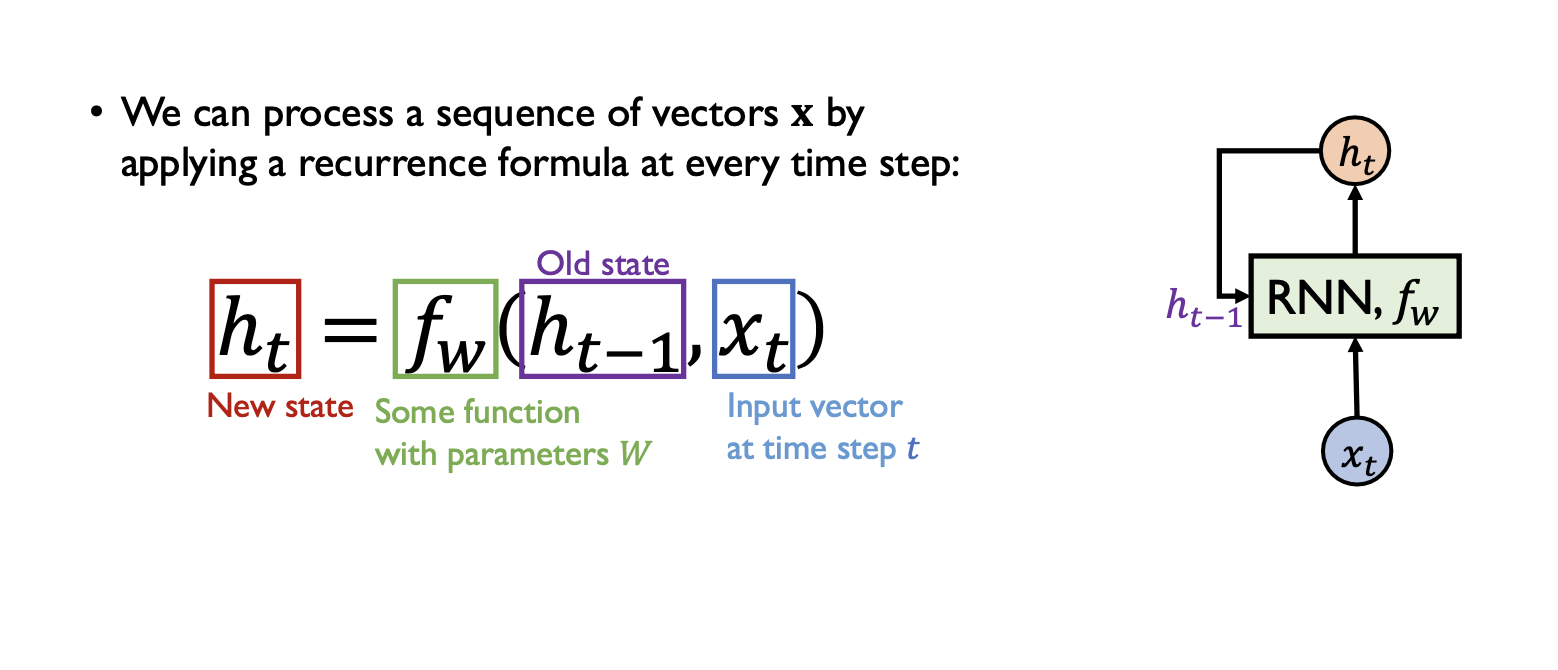
- 수식을 살펴보자
- 현재 time step에서의 입력신호와 이전의 time step에서 동일한 RNN 함수가 계산했던 Hidden state vector인 $h_{t-1}$을 입력으로 받아서 현재 RNN모델의 output인 $h_t$를 만들어주게된다.
- 여기서 중요한점은 매 time step마다 동일한 함수 $f_w$ 즉, 동일한 파라미터 셋을 갖는 layer가 반복적으로 수행된다는 것이다.
- 이 함수는 현재의 입력과 이전 타임 스텝에서 계산된 hidden state를 기반으로 현재의 hidden state를 생성한다.
-
그럼 여러 동작 과정에서의 RNN을 보자.
-
입력:
- $x^t$는 현재 시간 스텝 t에서의 입력 벡터를 나타낸다.
-
은닉 상태 (Hidden State):
-
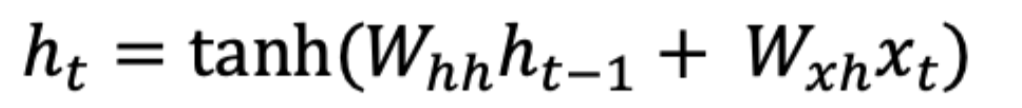 로 정의되며, 이는 이전 시간 스텝의 은닉 상태와 현재 입력의 가중합(fully-connected layer)에 대한 하이퍼볼릭 탄젠트 함수의 결과이다.
로 정의되며, 이는 이전 시간 스텝의 은닉 상태와 현재 입력의 가중합(fully-connected layer)에 대한 하이퍼볼릭 탄젠트 함수의 결과이다. -
$W_{hh}$ 는 이전 hidden state에서 현재 hidden state로의 가중치 행렬이며
$W_{xh}$는 현재 입력에서 hidden state로의 가중치 행렬이다.
-
RNN에 가장 적잘한 활성함수인 tan h를 써서 최종적으로 현재 타임 스텝의 벡터를 만들어주게된다.
-
-
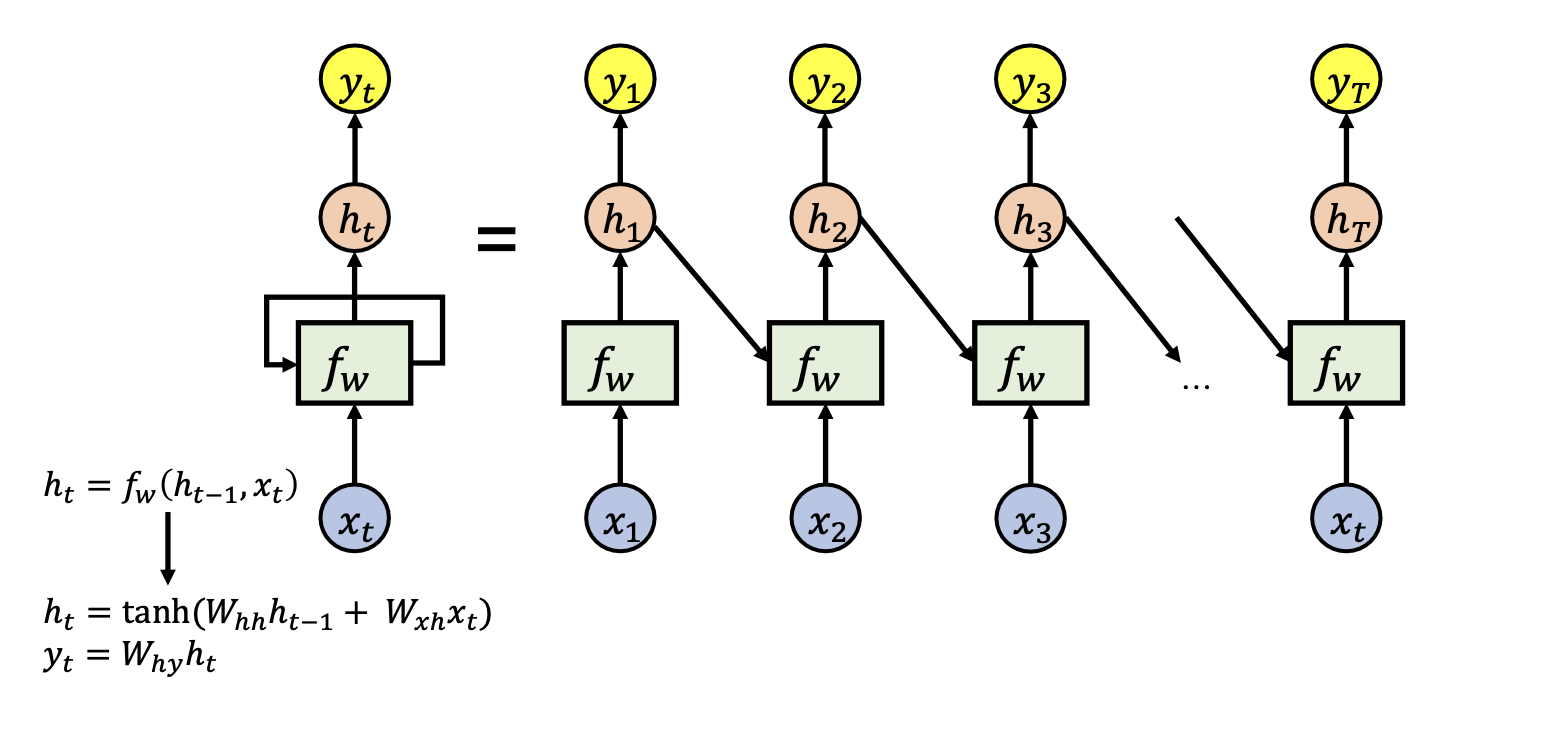
Output 계산
이 수식은 현재 타임 스텝 t에서의 출력인 $y_t$를 계산하는데 사용된다.
- $W_{hy}$는 hidden state에서 출력으로의 가중치 행렬이다.
-
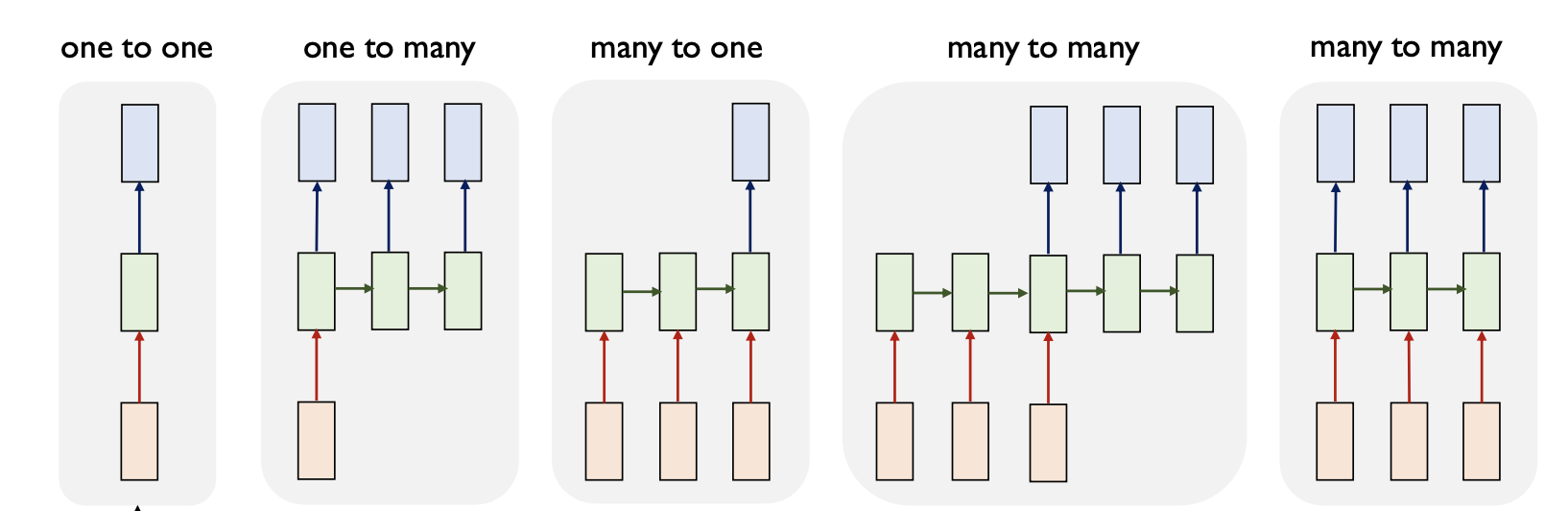
RNN 기반 시퀀스 모델링의 다양한 문제 설정
- 입력 및 출력이 어느 time step에 주어지고 예측 결과물이 나오느냐에 따라 여러가지 문제 설정을 할 수 있다.
-
One to one
- 한번에 하나의 data item을 독립적으로 예측 결과를 내어준다.
- Vanilla RNNs
- 기본 RNN은 간단하지만 그래디언트 소실 또는 폭주 문제로 인해 잘 작동하지 않는다. 그래서 실제로는 LSTM(Long Short-Term Memory) 또는 GRU(Gated Recurrent Unit)와 같은 고급 RNN 모델이 종종 사용된다.
-
One to many
- 최초 time step에 딱 한번 입력이 전체 다 주어지며 출력 결과물은 여러 time step에 걸쳐서 순차적인 예측 결과를 생성한다.
- image captioning task(이미지 캡션 작업)
- 추출된 이미지 특징을 입력으로 사용하여 순환 신경망(RNN)이나 변형된 모델을 통해 시퀀스(문장)을 생성한다.
-
Many to one
- 입력이 sequence 형태로 주어지되 실제 예측 결과물은 마지막 time step의 단일한 예측 결과를 생성한다.
- Sentiment Classification(감정 분류)
- 문장의 단어들을 순차적으로 넣고 마지막 hidden state의 결과에 따라 분류하게 된다.
-
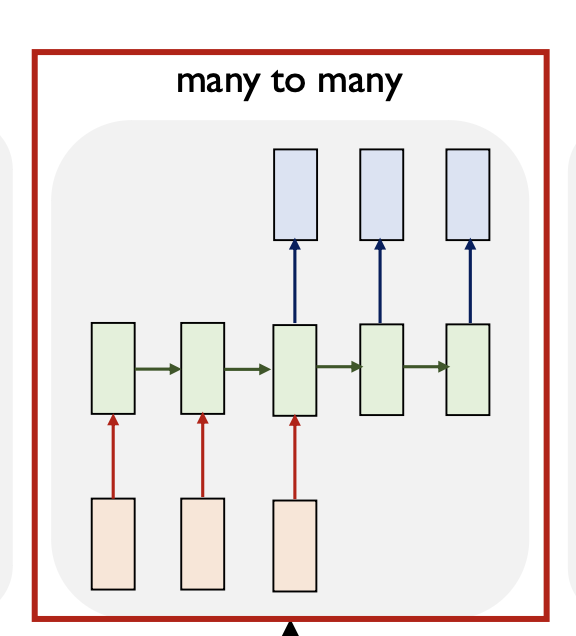
Many to Many
-
입력도 sequence 출력도 sequence의 형태이다.
-
machine translation task(기계 번역 작업)
-
영어 문장을 번역 하는 경우,
입력 문장의 정보를 다 받아서 정보를 처리한 이후에 문장에 대한 단어를 하나씩 하나씩 예측 해주는 형태이다.
-
-
-
Many to Many 변형
- 예측 결과물을 실시간으로 바로바로 예측결과를 생성하는 경우이다.
- Video Classificaition on Frame level
Character-level Language Model
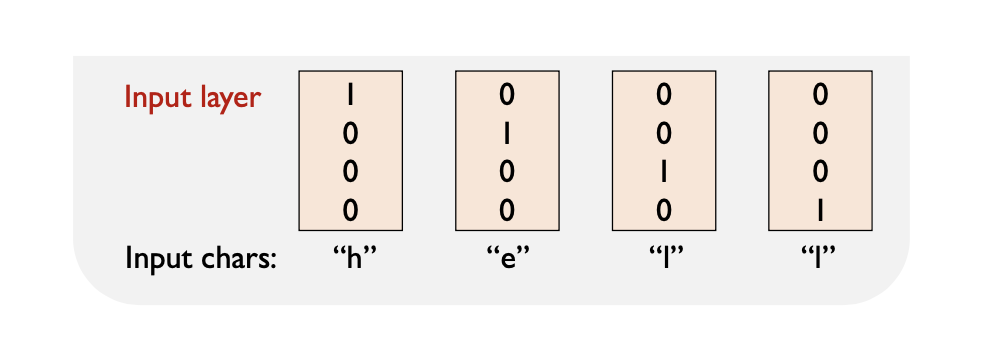
문자를 기반으로 언어 모델을 학습하는 방식으로, 텍스트를 예측하는 예시이다. 먼저 주어진 문자는 [h,e,l,o]이다.
-
Input Layer (입력층):
-
각 입력 문자(“h”, “e”, “l”, “o”)는 one-hot encoding을 통해 표현된다.
-
예를 들어, “h”는 [1, 0, 0, 0]으로 표현된다.
-
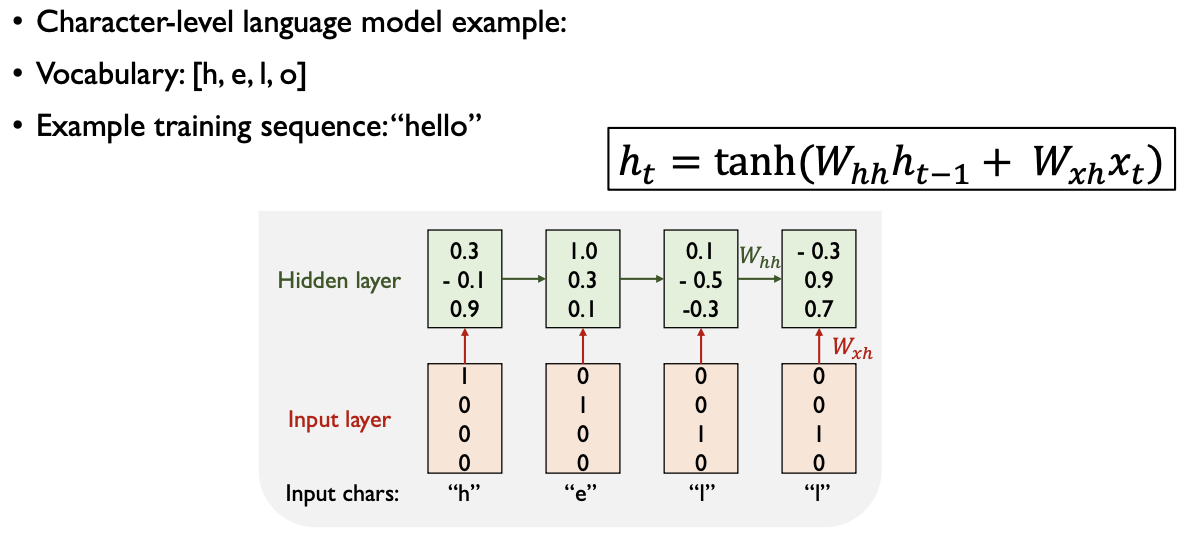
- Hidden Layer (은닉층):
- 입력층에서 전달된 one-hot encoding 벡터가 가중치 행렬에 곱해져 활성화 함수(tanh)를 거친다. 이를 통해 현재 시점의 hidden state가 계산된다.
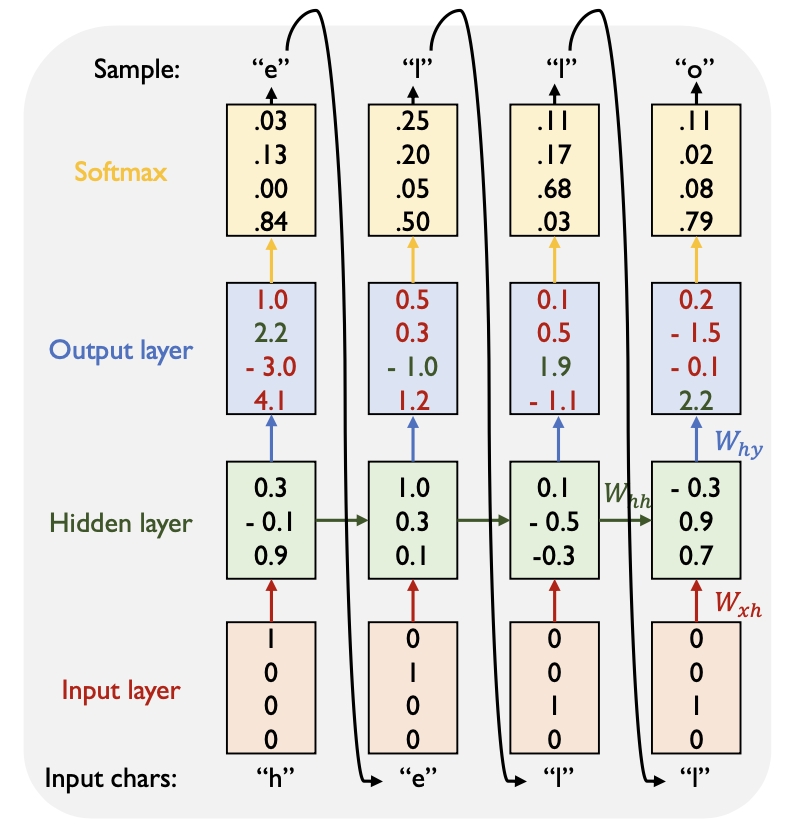
-
Output Layer (출력층) :
-
가장 큰 확률을 나타내는 차원의 결과로 예측하게 된다. 따라서 h e l l o 를 예측하게 된다.
-
Hidden layer에서 계산된 hidden state가 출력층으로 전달되고, softmax 함수를 통과하여 다음 문자에 대한 확률 분포를 생성한다. 학습할 때는 실제 다음 문자의 one-hot encoding과 비교하여 손실을 계산한다.
-
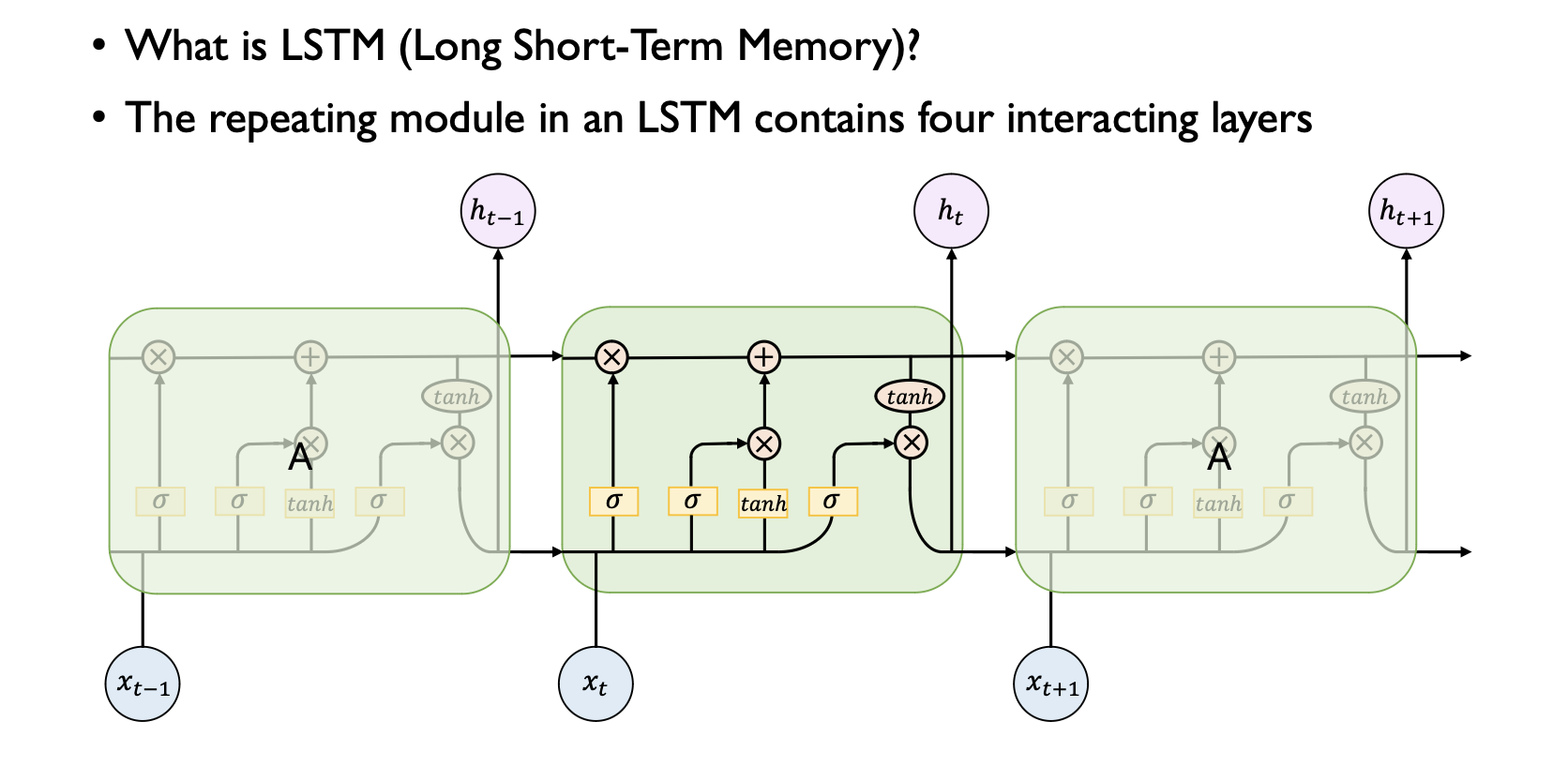
Long Short-Term Memory (LSTM)
LSTM은 RNN의 한 유형으로, 장기 의존성 문제를 해결하기 위해 고안됐다. 기본 RNN에서는 긴 시퀀스를 제대로 학습하기 어려웠지만, LSTM은 이 문제를 개선하기 위한 특별한 구조를 가지고 있다.
- Forget Gate (f):
- 현재 정보를 얼마나 잊을지를 결정하는 게이트이다.
- 이전 시점의 은닉 상태와 현재 입력을 고려하여 정보를 삭제할 정도를 결정한ㄷ.
- Input Gate (i):
- 현재 정보를 얼마나 기억할지를 결정하는 게이트이다.
- 현재 입력과 이전 시점의 은닉 상태를 고려하여 얼마나 많은 정보를 기억할지 결정한다.
- Gate Gate (g):
- 현재 정보를 얼마나 업데이트할지를 결정하는 게이트이다.
- 현재 입력과 이전 시점의 은닉 상태를 고려하여 정보를 업데이트할 정도를 결정한다.
- Output Gate (o):
- 현재 정보를 얼마나 다음 시점의 은닉 상태에 전달할지를 결정하는 게이트이다.
- 현재 입력과 이전 시점의 은닉 상태를 고려하여 다음 시점의 은닉 상태에 전달할 정보를 결정한다.
LSTM의 핵심 아이디어는 각 게이트가 얼마나 많은 정보를 통과시킬지를 학습하고, 게이트를 통과한 정보를 이전 시점의 셀 상태에 어떻게 업데이트할지를 학습하는 것이다. 이를 통해 LSTM은 장기 의존성을 쉽게 학습하고 기억할 수 있다.
Seq2seq and Attention Model
- Sequence to seqeunce 모델은 many to many 형태이다.
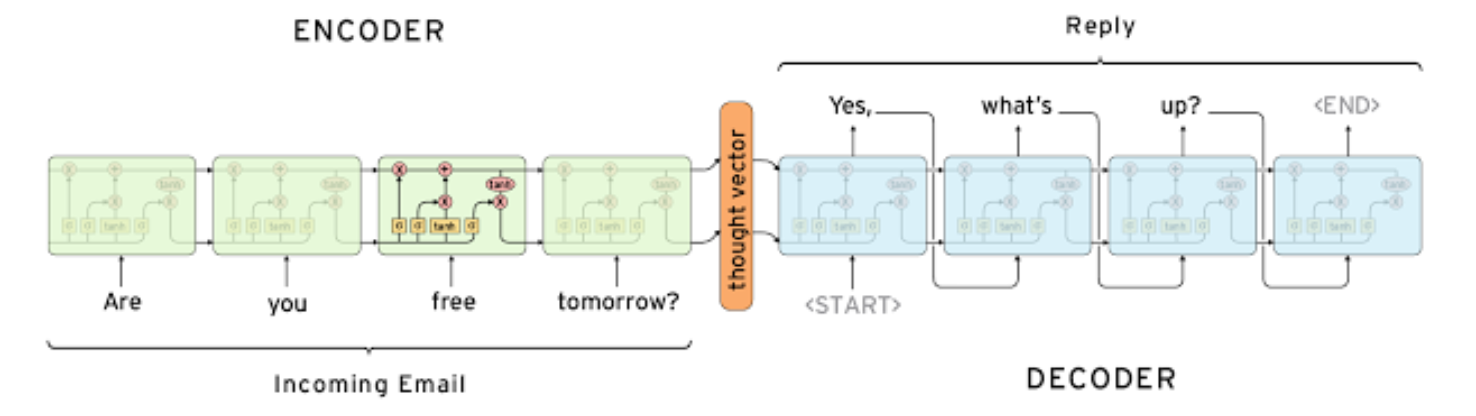
- Sequence to sequence model 의 대표적인 사례인 챗봇을 예를 보자.
- ENCODER
- 어떤 고객이 Are you free tommorw ? 라는 질문을 던졌다고 할 때 입력 문장은 단어별로 주어진다.
- 문장을 다 읽고 나서 마지막 time step 에서 나온 hidden state vector $h_t$는 주어진 입력 시퀀스의 모든 정보를 축적한 역할을 하는 vector이다.
- DECODER
- 디코더에서도 각 time step 별로 해당 단어을 예측한다.
-
예측 단계에서 가장 최초로 등장하는 특자문자로서 하나의 strat of sentence라는 단어를 입력으로 줘서 문장의 생성을 시작할 것이다라는 것을 알려준다. - 이전 step의 결과를 다음 step의 입력으로 줘서 단어를 연쇄적으로 예측하게 된다.
-
단어 생성이 끝났다는 걸의미하는 end of sentence token이 예측될 때까지 수행하게 된다.
- ENCODER
그렇지만 기본적인 Seq2Seq model에서는 하나의 이슈가 있다- 입력 시퀀스가 아무리 짧든 길든 매 time 마다 생성되는 RNN의 Hidden state vector는 특정한 같은 차원으로 이루어져야한다는 조건이 있다. 그래야만 출력 벡터가 다시 입력 벡터로 사용될 수 있기 때문이다.
입력 차원이 100차원이라면- 결국 축적해야하는 정보는 시간이 길어짐에 따라 점점 더 많아짐에도 불구하고 정보는 항상 같은 개수의 100개의 차원으로 이루어진 벡터에 욱여 담아야한다는 제약조건이 생긴다.
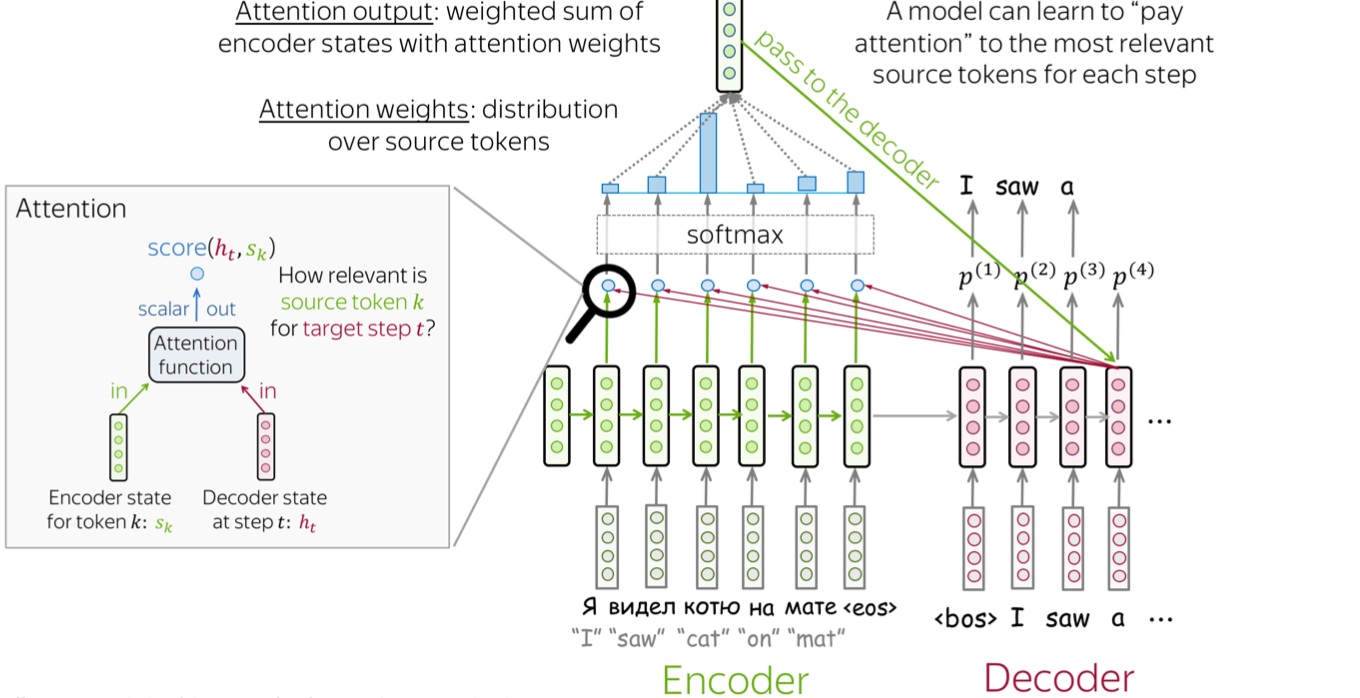
- 이러한 병목 현상을 해결하고자 나온 것이 Attention 모듈이다.
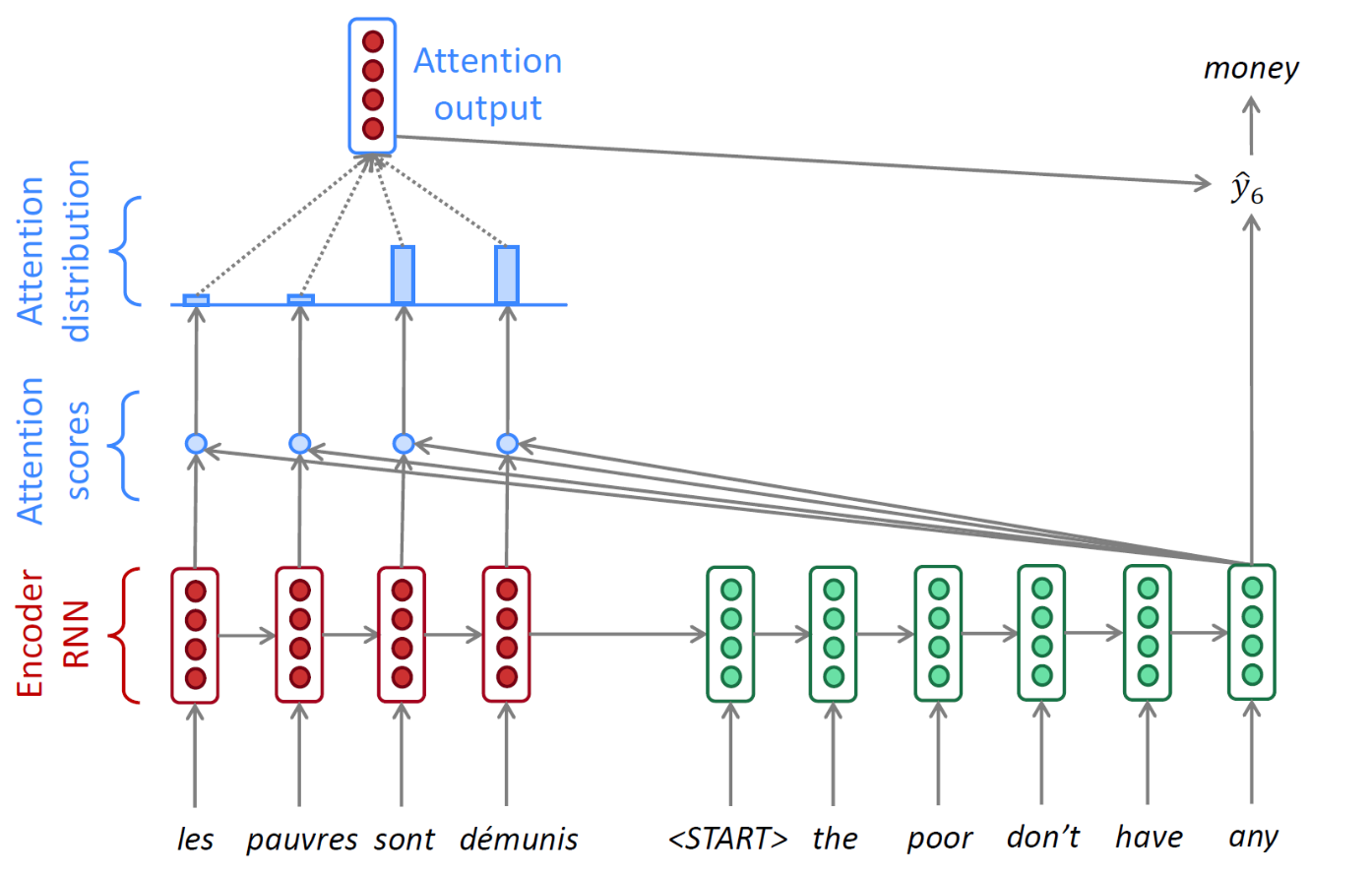
Attention
- 어텐션(Attention)은 Seq2Seq 모델의 병목 문제를 해결하기 위한 방법이다.
-
디코더의 각 시점에서 ENCODER 시퀀스의 다른 부분을 활용할 수 있도록 한다.
- 동작 과정을 살펴보자
- encoder에 있는 여러 Hidden state vector로부터 필요로 하는 정보를 취사선택해서 가장 유관하다고 생각하는 정보를 decoder의 추가적인 입력으로써 사용한다.
-
디코더의 첫 번째 “start of sentence” 토큰이 입력으로 주어질 때, 어텐션 메커니즘은 엔코더의 각 타임 스텝에서 hidden state vector와 디코더의 첫 번째 타임 스텝 hidden state vector 간의 유사도를 계산한다. 이를 통해 모델은 초기 상태에서 어떤 엔코더 hidden state vector에 주의를 기울일지를 학습한다.
- Attention scores
- 유사도는 내적을 사용하여 계산되며, 두 벡터 간의 내적 값이 클수록 더 관련성이 높은 정보임을 나타낸다.
- 이과정은 모델이 학습되면서 진행되며, 어텐션을 통해 디코더가 어떤 입력에 주의를 기울일지를 조절하게 된다.
- 이러한 과정을 통해 어텐션은 디코더가 초기 입력에 더 잘 적응하도록 도와준다.
- Attention distribution
- 내적 한 네개의 값인 유사도를 가지고 softamax 를 통과 시켜서 확률 벡터를 얻게 된다.
- 확률이 만약 85%, 3%, 5%, 7% 인 경우에 합이 1인 확률 vector를 encoder hidden state vector의 가중치로 반영해서 가중합을 뽑아냄으로써 attention model의 ouput의 만들게 된다.
- Attention output
- 가중합을 decoder의 output layer에 추가적인 입력으로 사용한다.
- 즉 decoder의 첫번째 time step의 hidden state vector와 가중합의 vector를 추가적인 입력으로 사용해서 총 8개 차원으로 이루어진 입력 vector 가 ouputlayer에 주어진다.
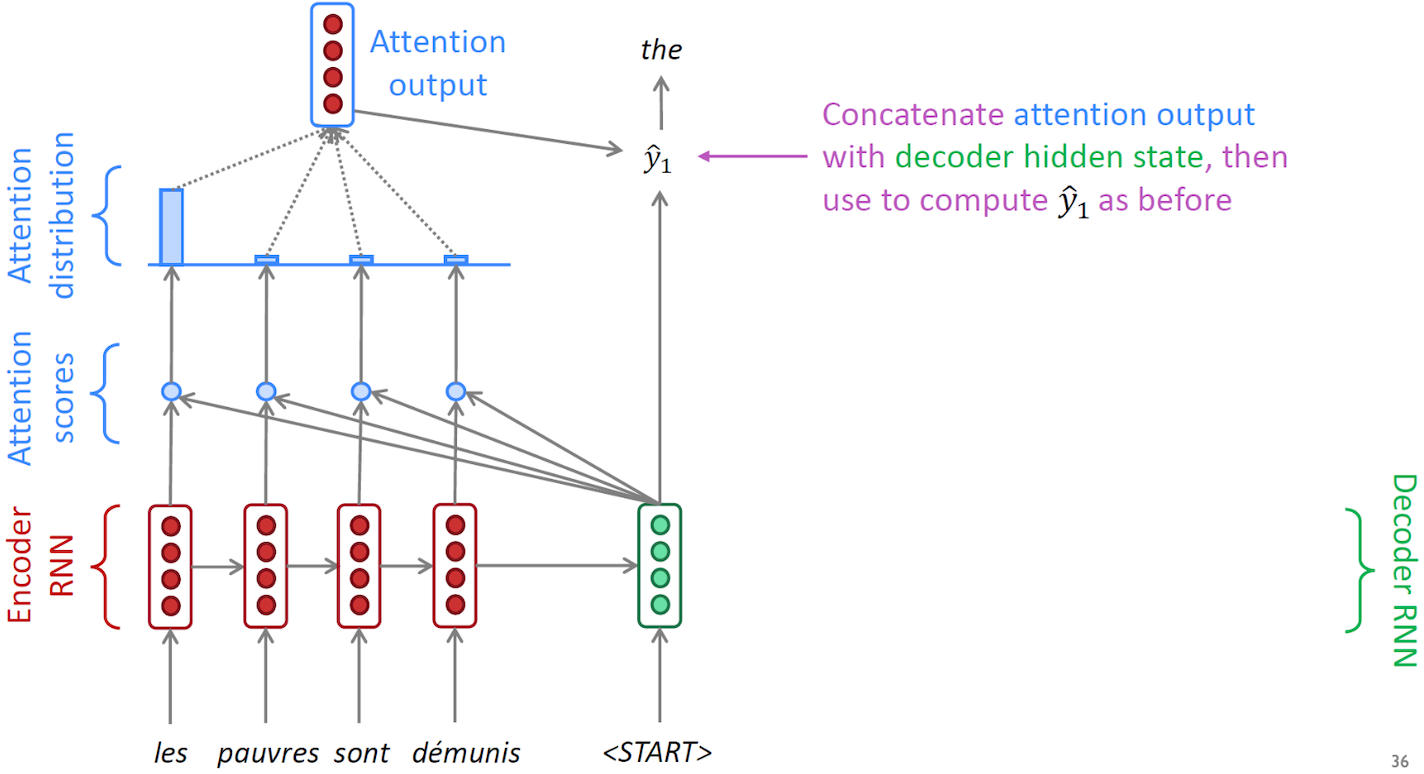
- 예측이 진행 될때마다 decoder의 새로운 hidden state vector는 새로운 유사도를 계산하는 기준이 되는 vector로 사용하여 다시 과정을 반복한다.
댓글남기기