[LG Aimers] 5-4. 딥러닝 (Transformer)
[공지사항] [해당 내용은 LG에서 주관하는 LG Amiers : AI 전문가 과정 4기 교육 과정입니다.] 강의를 듣고 이해한 내용을 바탕으로 직접 필기한 내용입니다. LG AI
5-4. 딥러닝(Deep Learning)
- 교수 : KAIST 주재걸 교수
- 학습목표
- Neural Networks의 한 종류인 딥러닝(Deep Learning)에 대한 기본 개념과 대표적인 모형들의 학습원리를 배우게 됩니다.
- 이미지와 언어모델 학습을 위한 딥러닝 모델과 학습원리를 배우게 됩니다.
Transformer 모델의 동작 원리
- Transformer는 주로 번역과 같은 자연어 처리 작업에 쓰이는 신경망으로, 단어 간 관계를 잘 이해하고 효과적으로 특징을 추출한다. Self-Attention과 다중 헤드 어텐션을 중심으로, 인코더와 디코더로 구성되며, 단어의 순서 정보를 위치 인코딩으로 유지한다. 기존의 RNN이나 LSTM보다 높은 성능을 보인다.
- 최근 굉장히 많이 각광받고 있는 모델이다.
-
기존에 배웠던 Seq2Seq with attention model의 좀 더 나은 개선판이라고 생각 할 수 있다.
그렇다면 기존의 Seq2Seq model에서는 어떤 이슈가 있을까?- Long-term Dependency 이슈가 있다.
- Forward propagation
- 주어진 시퀀스를 잘 encoding 해서 정보를 축적할 때 $h_3$라는 Hidden state vector에서 예전 정보를 잘 담겨 있어야만 한다.
- Backpropagation(역전파)
- 모델 학습과정에서도 마지막 time step 의 Hidden state vector인 $h_L$에서부터 여러 time step에 걸쳐서 gradient 정보가 변질되는 문제점들이 있다.
- Forward propagation
- Long-term Dependency 이슈가 있다.
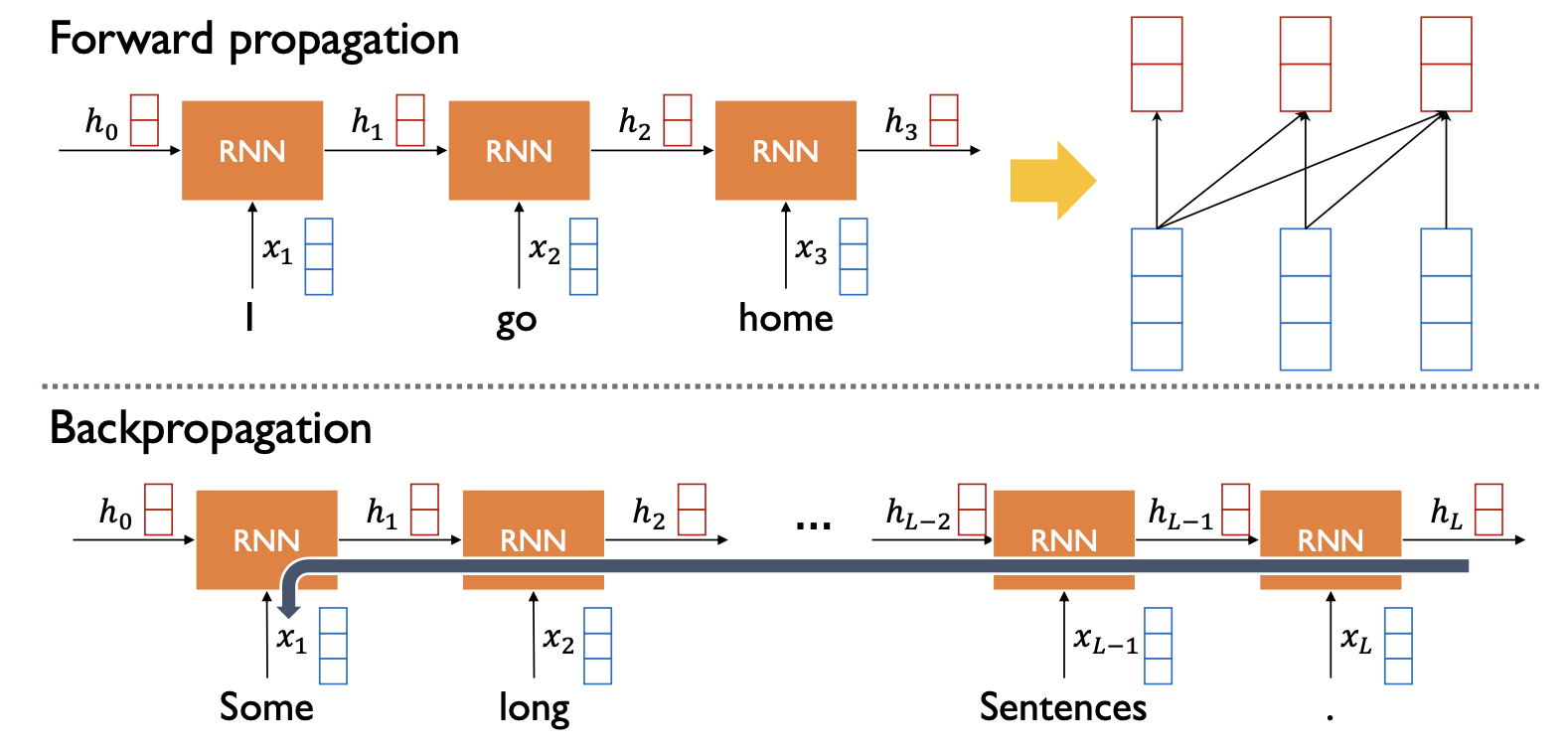
- 따라서 어떤 time step 에서든 바로바로 접근해서 필요한 정보를 잘 축적 하도록 Attention model을 이용한다.
Self- attention model
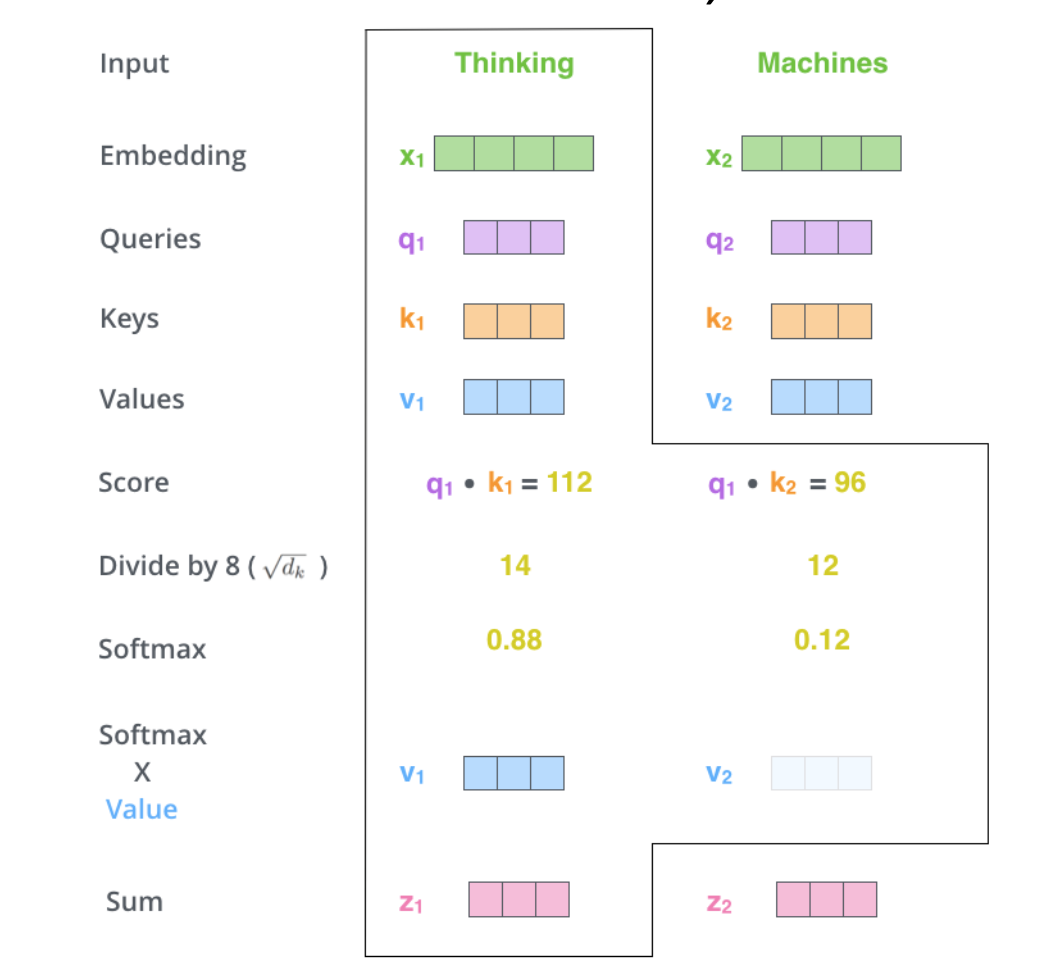
- 앞 서 설명했던 attention model과 달리 정보를 찾고자 하는 주체와 정보를 꺼내가려고 하는 재료 vector를 같은 주체라고 생각해보자. 동작과정은 다음과 같다.
- 먼저 I 라는 단어의 vectort를 decoder의 특정 Hidden state vector처럼 사용한다.
- 즉 자기자신과 내적, 옆에있는 $x2$, $x3$와 내적을 하여 유사도를 구한다.
- 유사도를 softmax 활성화 함수를 통과후 $x1$, $x2$, $x3$ 과의 가중합인 $h1$을 구한다.
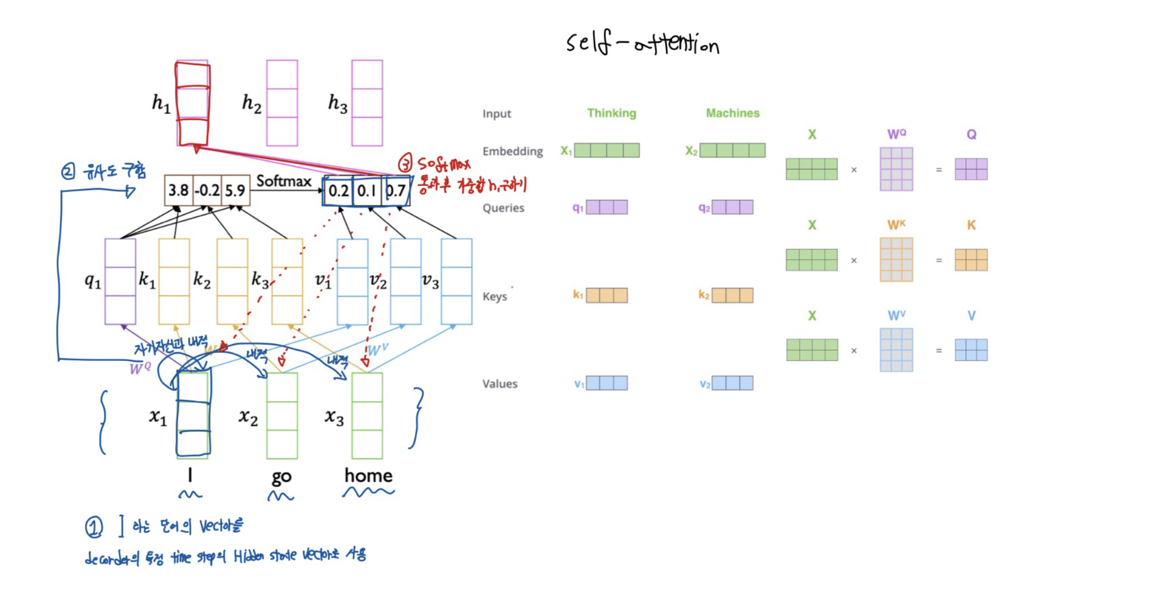
- 3가지 용도
- $q$(Query) : query vector 혹은 decoder hidden state vector처럼 사용
- $k$(Key) : 쿼리 벡터와 유사도를 구할때 사용되는 재료 vector
- $v$(Value) : softmax 를 적용해서 가중합을 구하게 하는 재료 vector
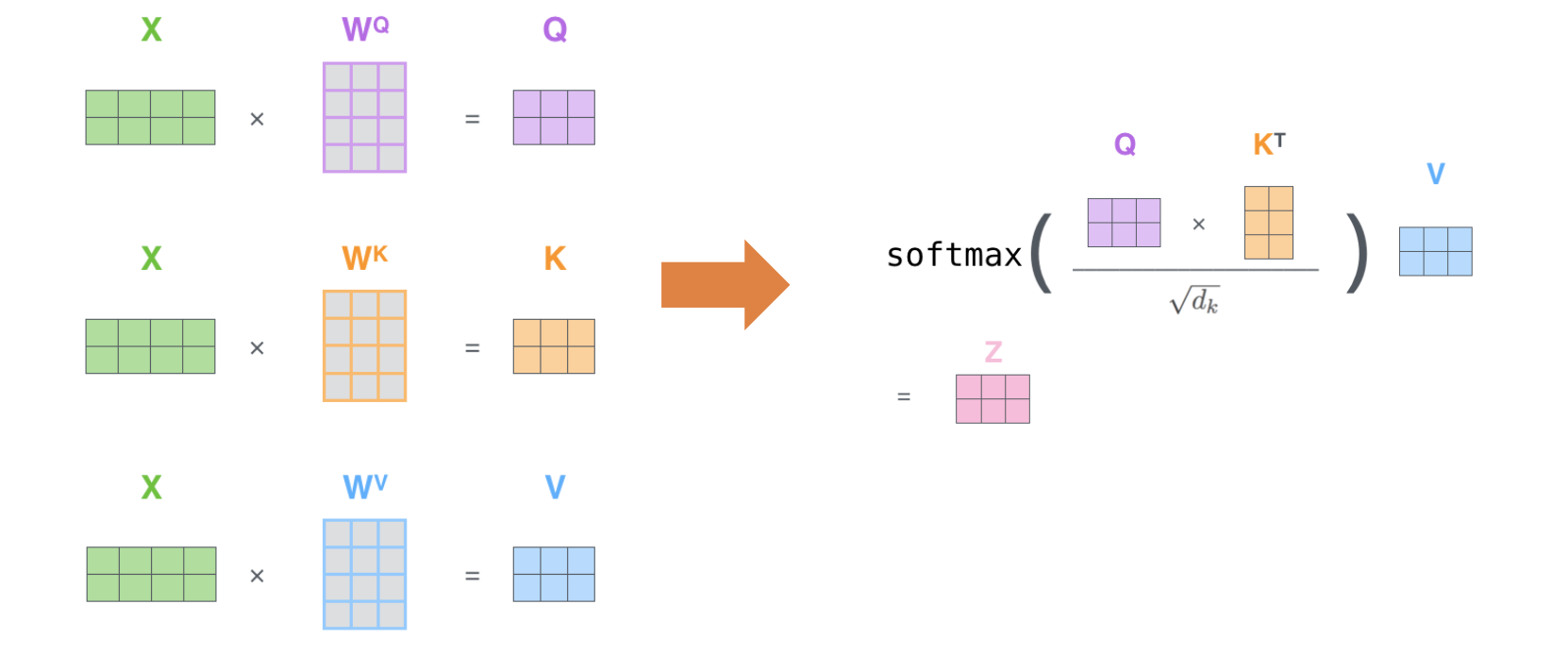
만약 x1, x2 두가지 단어를 합했을 때의 self-attention model을 생각해보자.- X는 x1, x2 vector를 합한 형태이며, 3가지 용도를 3가지 연산을 통해 얻을 수 있다.
- 수식은 다음과 같다.
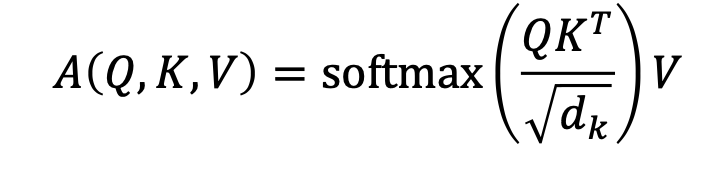
- $Q * K^T$는 Query와 Key의 내적을 의미하며, 이를 차원 $d$로 나누어준 것에 softmax 함수를 적용한다. 그리고 이렇게 얻은 가중치를 $Value$에 곱하여 최종 $Attention$ 값을 얻는다.
Transformer: Multi-head Attention
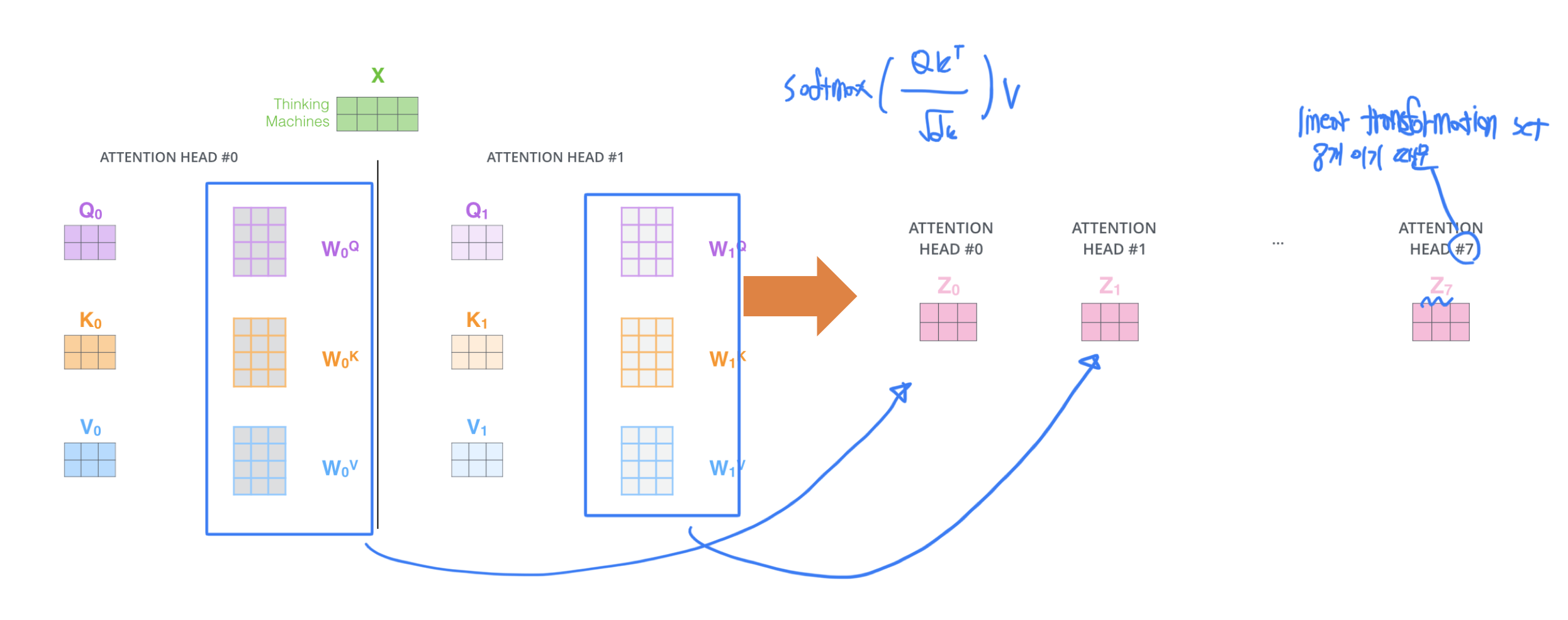
- problem
- 주어진 sequence의 각각의 입력 vector들을 encoding 할 때 어떤 특정한 $W_q$, $W_k$, $W_v$를 사용하면 하나의 유형으로 하나의 정해진 변환으로 attention module을 사용해서 sequence를 encoding하게 된다.
- 특정 단어를 encoding할 때 이 사람이 어떤 행동을 했나, 어떤 시간에 했나 처럼 서로 다른 기준으로 정보를 추출해야 하는 필요성.
- Solution
- 선형 결합 set인 $W_q$, $W_k$, $W_v$ 를 여러개를 둔다. 각각의 set를 통해 변환된 Q, K, V를 사용해서 attention model을 통해 encoding 한다. 그 다음엔 각각의 set에 선형 변환을 사용해서 나온 output을 나중에 Concat하는 형태로 확장한다.
- attention을 여러개의 linear transformation set($W_q$, $W_k$, $W_v$)를 사용해서 attetion을 수행한다 해서 multi - head라고 한다.
- 각기 서로 다른 기준으로 encoding을 해서 만들어진 결과 vector $Z$ 이다
- 차원의 방향으로 쭉 concat을 한다면 각 단어들을 다양한 기준에 의해서 encoding한 self-attention module의 output vector를 얻게 된다.
- 원하는 차원으로 만들기 위하여 추가적인 linear transformation을 거치게 된다.
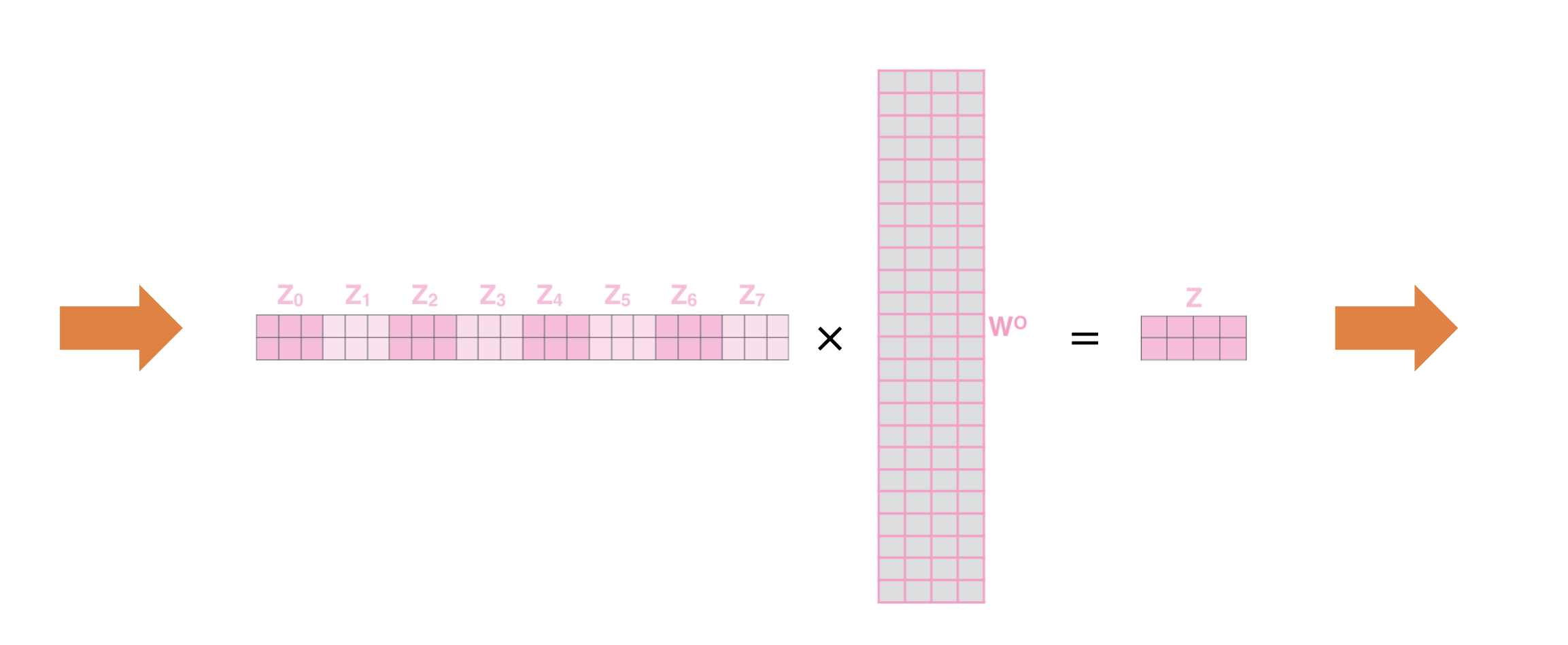
- 앞서 말했던 Long-term Dependency 이슈는 각각의 단어들이 query로 사용돼서 전체 sequence에 존재하는 각 단어들의 직접적으로 유사도를 구하고 거기서 유사도가 높은 단어를 직접적으로 꺼내갈 수 있다는 장점이 있다.
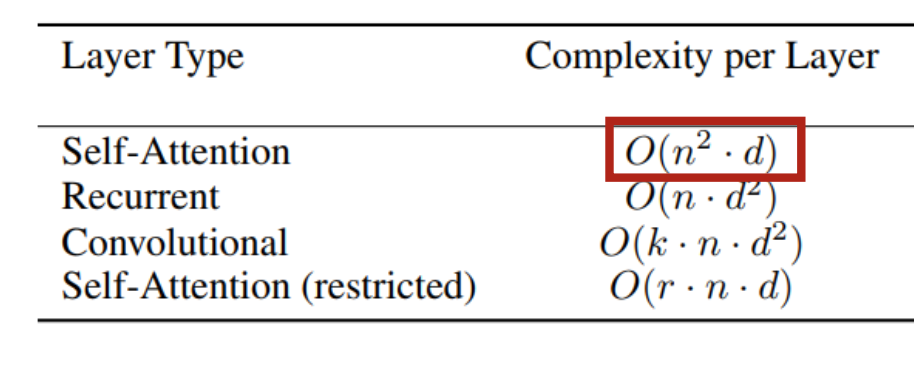
하지만 self attention의 치명적인 단점은 무엇일까?- 바로 Memory 요구량이다.
- 바로 Memory 요구량이다.
Transfomer: Block-Based Model
- Transfomer 모델이 전체적으로 어떻게 구성되어 있을까?
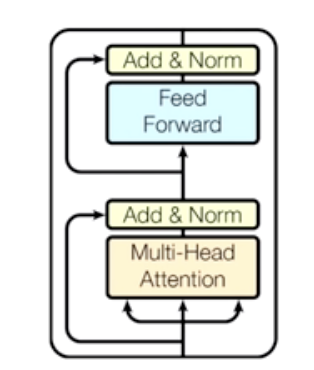
-
Multi-Head Attention
-
입력 시퀀스: 예를 들어, “I go home”이라는 세 개의 단어로 이루어진 입력 시퀀스가 있다고 가정합니다. 각 단어에 해당하는 벡터가 입력으로 주어진다.
- Query, Key, Value 생성 : 각 단어 벡터는 선형 변환을 통해 Query($Q$), Key($K$), Value($V$)로 변환됩니다. 선형 변환에 사용되는 가중치 행렬은 각각 $W_q$, $W_k$, $W_v$이다. 따라서, 각 단어 벡터 $x_i$에 대해 다음과 같이 변환된다:
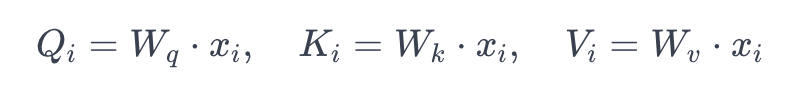
- 여기서 $Q_i$, $K_i$, $V_i$는 각각 $i$번째 단어에 대한 Query, Key, Value 벡터를 나타냅다.
- Self Attention 계산: 계산된 $Q$, $K$, $V$ 벡터를 사용하여 self attention을 계산한다.
- Multi-Head Attention : Multi-Head Attention은 위의 과정을 여러 개의 head로 병렬적으로 수행한다. 각 head는 독립적으로 학습되는 $W_q$, $W_k$, $W_v$를 가지고 있다. 각 head의 결과를 합치기 위해 최종 출력은 각 head의 결과를 연결(concatenate)하고 선형 변환을 적용하여 얻는다.
-
-
Add & Norm
- Skip connection : 스킵 연결은 층을 건너뛰어 원래 입력을 층의 출력에 직접 더하는 방식으로 동작한다. 이렇게 함으로써 기존의 입력 신호를 다음 층으로 직접 전달함으로써 그라디언트 전파를 돕고, 정보 손실을 줄여 모델의 학습을 안정화시킬 수 있다.
- 쉽게 말하면, Add & Norm에서의 “Add” 부분은 스킵 연결을 통해 기존 입력 정보를 보존하고, “Norm” 부분은 출력을 정규화하여 안정적인 학습을 돕는 구조이다.
- Feed Forward
- 이는 정보의 전달이 입력에서 출력으로 한 방향으로만 진행되는 구조를 갖고 있다. 각 층의 뉴런은 이전 층의 모든 뉴런과 연결되어 있으며, 각 연결에는 가중치가 할당되어 있다.
- Add & Norm
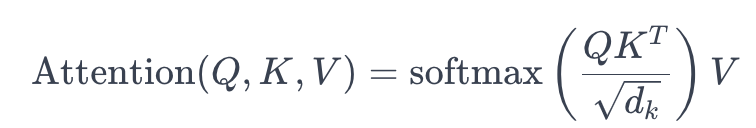
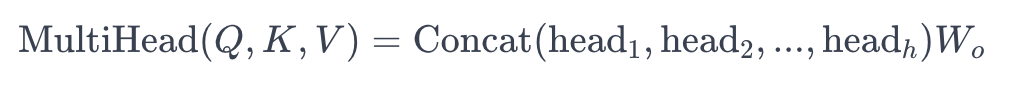
For example
- 입력 문장 임베딩:
- “나는 집에 간다”라는 문장을 임베딩하여 각 단어에 대한 벡터 표현을 얻습니다.
- Query, Key, Value 생성:
- 각 단어 벡터는 Query, Key, Value로 변환됩니다. 이를 위해 각각의 단어 벡터에 대해 다른 가중치 행렬 $W_q$, $W_k$, $W_v$를 사용합니다.
- $Q_{나는}$ = $W_q$ * “나는” 벡터
- $K_{나는}$ = $W_k$ * “나는” 벡터
- $V_{나는}$ = $W_v$ * “나는” 벡터
- 위의 과정을 “집에”와 “간다”에 대해서도 수행합니다.
- 각 단어 벡터는 Query, Key, Value로 변환됩니다. 이를 위해 각각의 단어 벡터에 대해 다른 가중치 행렬 $W_q$, $W_k$, $W_v$를 사용합니다.
- Attention Score 계산:
- 각 단어에 대한 Query, Key를 사용하여 attention score를 계산합니다. 주로 dot-product attention을 사용합니다.
- $\text{Attention Score}{나는, 나는}$ = $Q{나는} \cdot K_{나는}^T$
- $\text{Attention Score}{집에, 나는}$ = $Q{집에} \cdot K_{나는}^T$
- $\text{Attention Score}{간다, 나는}$ = $Q{간다} \cdot K_{나는}^T$
- 각 단어에 대한 Query, Key를 사용하여 attention score를 계산합니다. 주로 dot-product attention을 사용합니다.
- Softmax 및 Weighted Sum:
- Attention Score에 softmax 함수를 적용하여 각 단어의 attention weight를 계산합니다.
- 이를 사용하여 Value에 가중합을 수행하여 최종 출력을 얻습니다.
- $A_{나는}$ = $\text{softmax}(\text{Attention Score}{나는, 나는}, \text{Attention Score}{집에, 나는}, \text{Attention Score}_{간다, 나는})$
- $\text{Output}{나는}$ = $A{나는} \cdot V_{나는}$
- $\text{Output}{집에}$ = $A{집에} \cdot V_{집에}$
- $\text{Output}{간다}$ = $A{간다} \cdot V_{간다}$
- Multi-Head Attention:
- 멀티헤드 어텐션은 여러 개의 head를 사용하여 다양한 관점에서 정보를 추출합니다.
- 각 head에서 위의 과정을 독립적으로 수행하고, 결과를 합칩니다.
- 출력 결합:
- 각 head의 결과를 연결(concatenate)하고, 이를 통해 최종적인 멀티헤드 어텐션의 출력을 얻습니다.
- $\text{Final Output}$ = $\text{Concat}(\text{Output}{나는}, \text{Output}{집에}, \text{Output}_{간다}, \ldots)$
- 각 head의 결과를 연결(concatenate)하고, 이를 통해 최종적인 멀티헤드 어텐션의 출력을 얻습니다.
이렇게 멀티헤드 어텐션을 통해 입력 문장 “나는 집에 간다”에 대한 다양한 관점에서의 정보를 추출하고, 이를 조합하여 “I go home”과 같은 최종적인 번역을 얻을 수 있습니다.
댓글남기기