[LG Aimers] 5-5. 딥러닝 (Self-Supervised Learning and Large-Scale Pre-Trained Models)
[공지사항] [해당 내용은 LG에서 주관하는 LG Amiers : AI 전문가 과정 4기 교육 과정입니다.] 강의를 듣고 이해한 내용을 바탕으로 직접 필기한 내용입니다. LG AI
5-5. 딥러닝(Deep Learning)
- 교수 : KAIST 주재걸 교수
- 학습목표
- Neural Networks의 한 종류인 딥러닝(Deep Learning)에 대한 기본 개념과 대표적인 모형들의 학습원리를 배우게 됩니다.
- 이미지와 언어모델 학습을 위한 딥러닝 모델과 학습원리를 배우게 됩니다.
자가지도학습 및 언어 모델을 통한 대규모 사전 학습 모델
- 학습 data로 볼 때 주어진 data item과 특정 task를 기준으로 했을 때 거기에 필요로 하는 부가적인 label이 추가정보로 붙게 된다.
- 만약 고양이, 개 를 구분하는 data일때 수집 시 일일이 label을 해줘야하는 문제점이 있다. 이 때문에 수많은 인터넷에 생성된 data를 곧바로 학습 data 사용하기에 문제점이 많다.
- 따라서 이러한 labeling 과정이 없이도 원시 data만으로 학습시키기 위해 시작된 모델이다.
What is Self-Supervised Learning
- 원시 data혹은 별도의 추가적인 label이 없는 입력 data중 일부를 가려놓고 그 일부를 잘 복원, 예측 하도록 학습하는 task이다.
- 대표적인 예로 컴퓨터 비전의 image in- painting 이 있다.
- 가려진 이미지의 실제 픽셀값을 잘 복원하기 위해 물체의 여러가지 의미들을 잘 파악해야한다.

- 두번째 예로는 컴퓨터 비전의 직소 퍼즐이 있다.
- 특정 size의 패치로 자르고 패치 순서를 임의로 바꾼다.
- 사람이 퍼즐을 풀어내듯이 머신러닝이 순서정보나 위치를 예측하도록 학습하게 되면 유의미한 정보를 배우게 된다.

Transfer Learning from Self-Supervised Pre-trained Model
-
Transfer 모델은 자기지도학습을 통해 task를 풀기위해 수집한 data를 가지고 학습을 한다.
- task A : 다양한 layer중에서 앞쪽에 위치한 layer들은 공통적으로 다른 task들에게 적용가능한 정보를 추출하는 역할을 한다.
- task B : 그 후 원하는 특징의 target task를 가진 layer를 추가해서 학습을 진행한다.
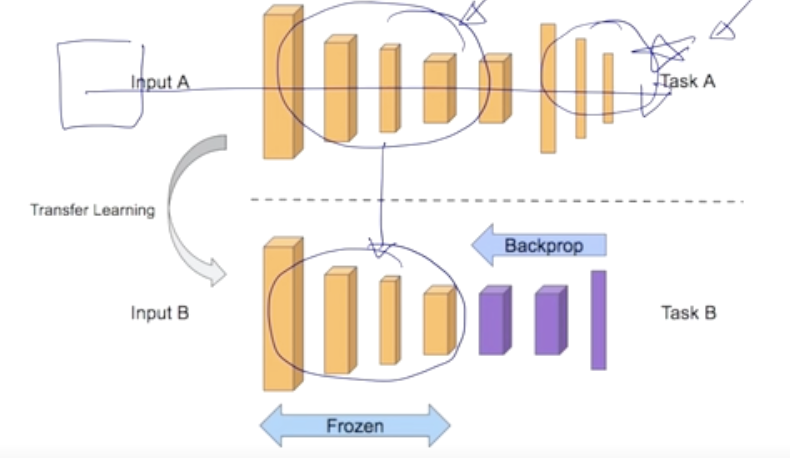
-
이러한 대규모 data를 통한 자가 지도학습을 통해 사전 학습된 모델은 자연어 처리 분야에서 많은 발전을 거두었다.
BERT
- 대규모 data를 통한 자가 지도학습을 통해 사전 학습된 모델이다
-
Pre-training of Deep Bidirectional Transformers for Language Understanding(언어 이해를 위한 깊은 양방향 트랜스포머의 사전 훈련)
-
모델의 구조 및 입력 출력 setting을 알아보자.
-
Bert모델은 transformer model에 encoder에 자가 지도 학습이라는 형태로 학습시키기 위해서 대규모 text data를 학습 data로 사용한다.
-
자가지도 학습의 기본 개념인 입력 데이터의 일부를 가리고 예측하는 관점에서 입력 문장의 일부 단어를 [MASK]로 대체한다. [MASK] 에 원래 어떤 단어가 있었는지 마추는 방식으로 학습하게 된다.
- next sentence prediction : 사전 훈련 단계에서 사용되는 작업 중 하나이다. 이 작업은 두 개의 문장이 주어졌을 때, 이 두 문장이 실제 문서나 맥락 상에서 연속적으로 등장하는지 여부를 모델이 판단하도록 하는 것이다. 즉, 두 문장 간의 의미적인 관계를 파악하는 것이 목표이다. - 첫번째 입력으로**[CLS] **라는 스페셜 토큰을 주고, 두 문장 사이와 끝에 separator token인 **[SEP]**을 추가해 준다.- 각각의 단어가 encoding 된 vector가 된다.
- 첫 번째 문장의 [CLS] 가 인코딩된 토큰 벡터가 다음 문장 예측 NSP(next sentence prediction)을 위한 출력 레이어에 입력으로 사용된다. 이렇게 함으로써 두 문장이 연속적으로 등장했는지에 대한 이진 분류 작업이 이루어진다.
- [MASK]가 인코딩된 토큰 벡터가 출력 레이어에 입력으로 줘서 단어를 맞추는 작업 MLM이 이루어진다.
-
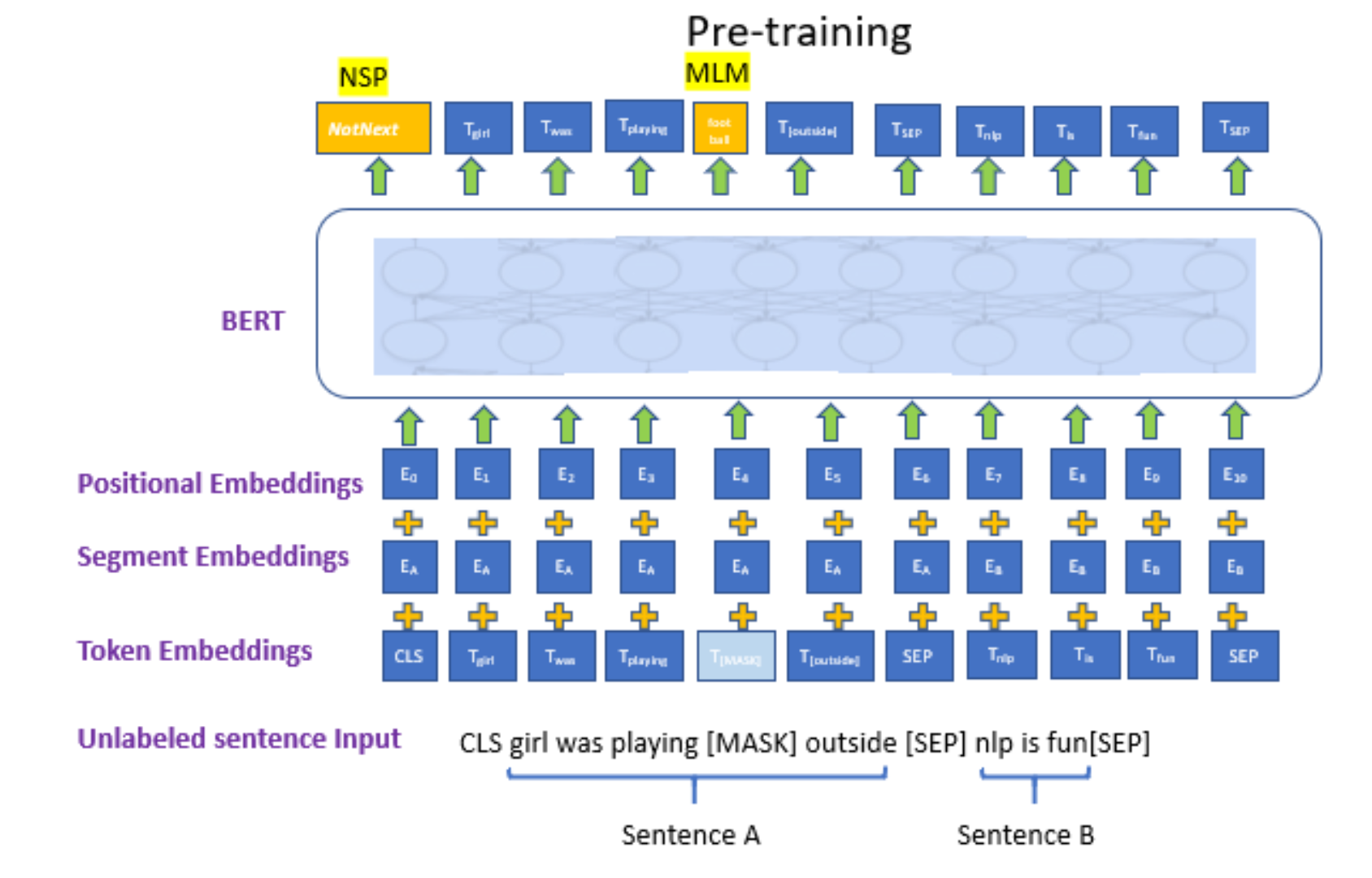
그렇다면 NSP, MLM이란 무엇일까?
- Masked Language Model(MLM)
- 주어진 입력 문장에 대해서 random하게 특정 비율, 확률로 mask token을 대체 할지 그냥 둘지에 대한 전처리를 수행한다.
- 15%의 비율로 MAKING
- 예를 들어, 100개의 단어가 있는 문장이 있다고 가정하면, 15%의 비율로 총 15개의 단어가 선택되어 [MASK] 토큰으로 대체된다.
- 마스킹된 단어들에 대한 작업:
- 이후 모델은 이 [MASK] 토큰을 가진 단어들에 대해 다음과 같은 예측 작업을 수행한다.
- 80%의 경우: [MASK] 토큰을 정확하게 맞춰야 한다.
- 10%의 경우: 무작위로 선택된 다른 단어로 대체한다.
- 10%의 경우: 해당 단어를 그대로 유지하고 정확하게 맞춰야한다. 이는 모델이 자기 자신이 학습한 단어에 대해 더욱 강력한 표현을 학습하도록 도와준다.
- 이후 모델은 이 [MASK] 토큰을 가진 단어들에 대해 다음과 같은 예측 작업을 수행한다.
- Next Sentence Prediction(NSP)
- 기본적으로 학습할때 두개의 문장이 주어지고 separator token으로 구분된다. 이때 [CLS] 가 인코딩된 토큰 벡터로 부터 두 문장이 어떠한 문서에서 연속되게 등장했던 연관성 있는 문장인지 binary classificaion 한다.
Details of BERT
-
Model Architecture
- BERT BASE: L(layer 수) = 12, H(차원 수) = 768, A(헤더 수) = 12
- BERT LARGE: L = 24, H = 1024, A = 16
-
Input Representation • WordPieceembeddings(30,000WordPiece) • Learned positional embedding • [CLS] – Classification embedding • Packed sentence embedding [SEP] • Segment Embedding
-
Pre-training Tasks • Masked LM
• Next Sentence Prediction
**Various Fine-Tuning Approaches **
-
BERT는 사전 훈련(pre-training) 단계에서 대규모의 데이터로 학습된 다목적 언어 모델로서, 이를 다양한 자연어 처리(NLP) 작업에 맞게 특화시키기 위해 세부 작업에 맞게 파인 튜닝(fine-tuning)이 필요하다.
- 품사를 예측하는 classificaion task
- 입력 문장의 각각의 단어를 입력으로 주고, output으로 나온 hidden state vector에 추가적으로 linear layer를 하나 달아서 그 layer는 품사를 예측하는 classification task를 수행하게 한다.
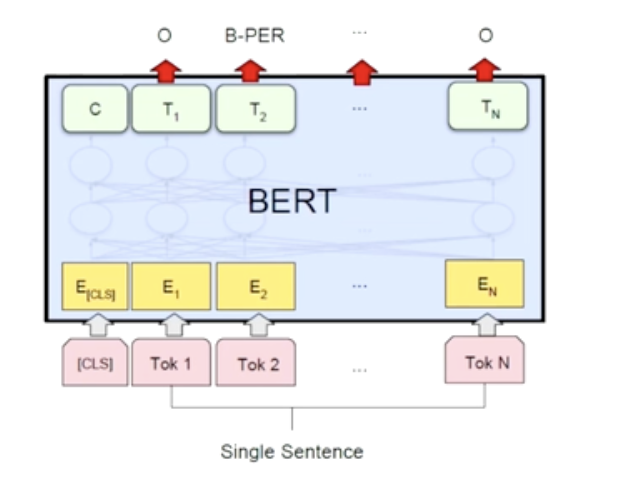
- 긍정 부정을 예측하는 classificaion task
- CLS 에 추가적인 fully connected layer를 하나 달아서 긍정인지 부정인지를 예측하도록 한다.
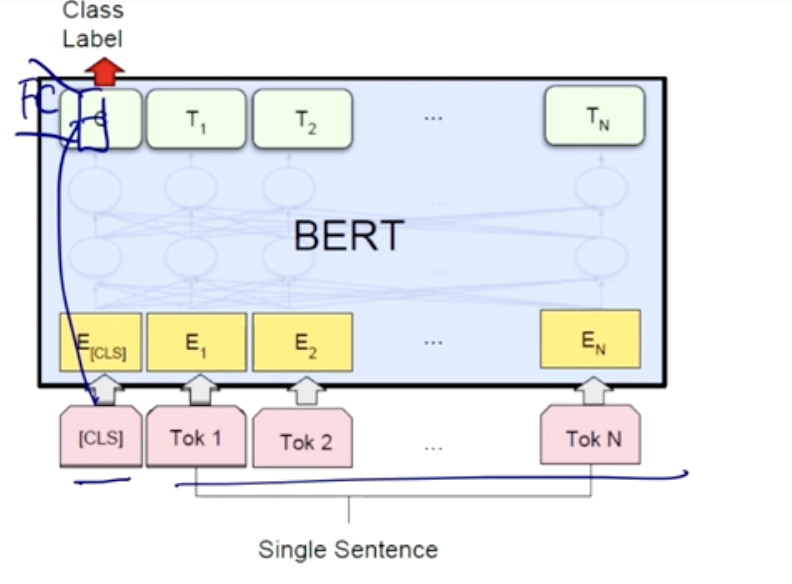
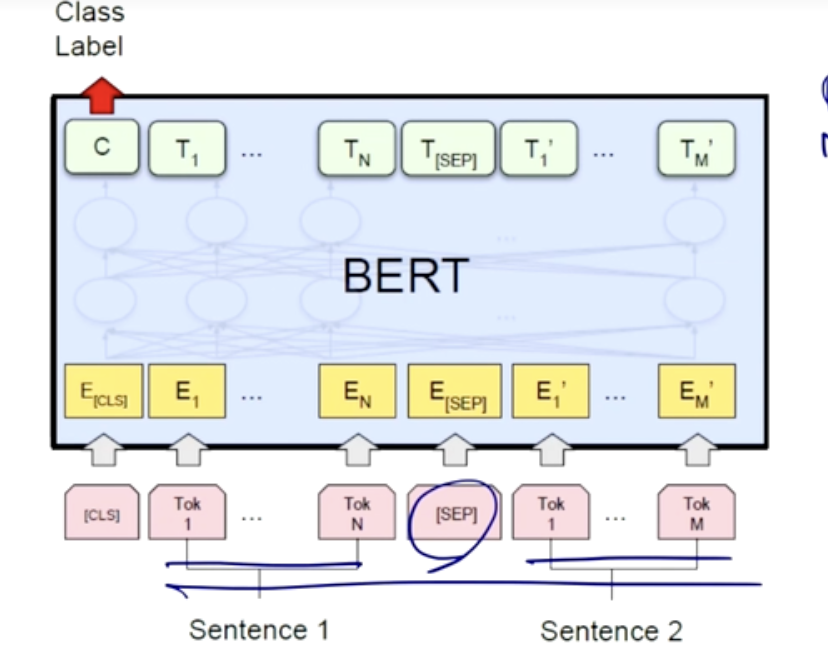
- 문장 두개 논리적인 관계를 분류하고자 하는 task
- 두개의 문장을 구분하는 [SEP] 라는 토큰을 주게 된다.
- [CLS] 토큰은 문장 전체를 대표하는 벡터로 사용된다. [CLS] 토큰 다음에는 classifier head가 추가되는데. Classifier head는 fully-connected layer 및 출력층을 포함하는 부분으로, 이 부분이 모델의 최종 출력을 생성한다.
- 해당 classifier head의 출력은 두 클래스(두 문장이 관련이 있음 또는 관련이 없음)에 대한 확률을 나타내는데, 일반적으로 softmax 활성화 함수를 사용하여 계산된다.
-
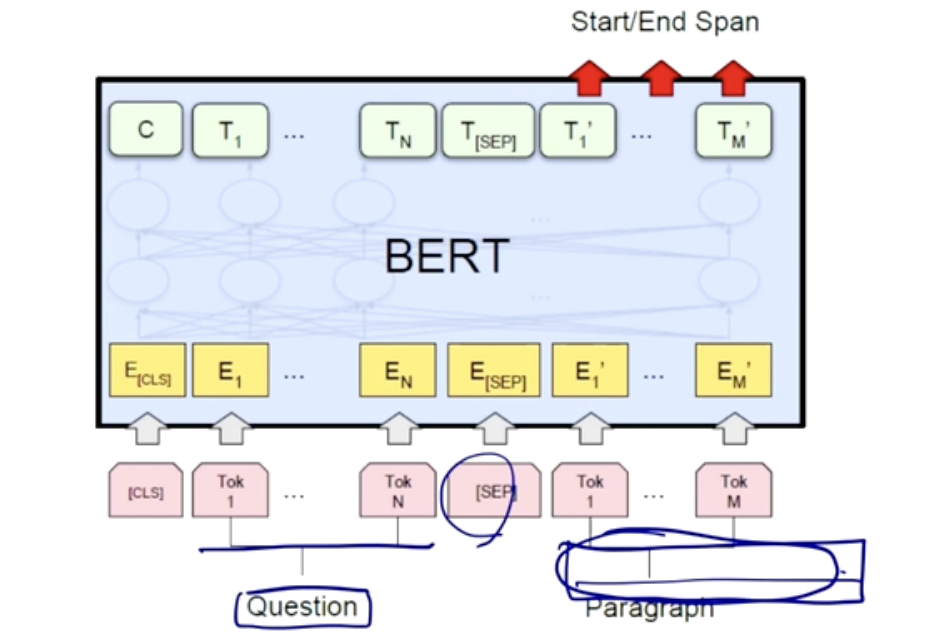
기계 독해 task
-
기계 질문 문장과 지문에 대한 문장을 [SEP] 로 나눠 구성한다.
-
지문에 대한 문장에서 특정한 문구를 발췌해서 예측하도록 한다.
-
Fully-Connected Layer 활용
-
지문에 대한 문장에서 특정 문구를 예측하기 위해, 해당 문구에 대한 정보가 있는 단어들이 모델의 fully-connected layer를 통과한다.
-
각 단어는 같은 fully-connected layer를 통과하고, 이를 통해 단어의 의미적 표현이 얻어진다.
-
- Scalar 값 예측:
- 각 단어가 통과한 fully-connected layer의 출력을 합하여 하나의 scalar 값으로 만듭니다. 이 scalar 값은 특정 문구에 대한 예측의 기여도를 나타낸다.
-
Softmax Classification:
-
Scalar 값은 softmax classification을 거쳐 예측 확률로 변환된다.
-
모델은 특정 문구가 지문 내에서 어디에 위치하는지를 확률적으로 예측하게 된다.
-
-
-
GPT-1/2/3: Generative Pre-Trained Transfomer
- “생성형 사전 훈련 트랜스포머”이다.
- GPT 모델 또한 트랜스포머(Transformer) 아키텍처를 기반으로 하며, 사전 훈련(pre-training) 단계에서 대량의 텍스트 데이터를 사용하여 다양한 자연어 처리 작업에 대한 일반적인 언어 이해 능력을 스스로 학습한다. 그 후에 fine-tuning을 통해 특정 작업에 맞게 조정될 수 있다.
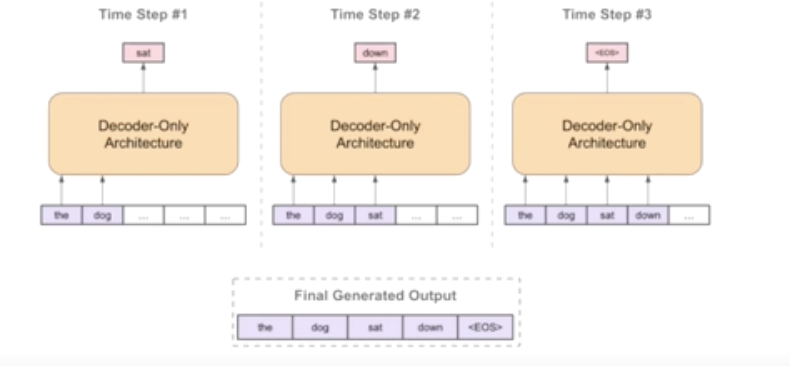
- tansfomer model에서 DECODER를 사용한다.
- 단어 단위의 text data로 부터 문장들을 가져오고
- 문장으로부터의 입력에서 다음 단어를 예측하고 또 그 단어로 다음 단어를 예측하도록 하는 방식이다.
GPT - 2
- 특히 GPT-2 모델은 self-attention block을 굉장히 깊이 쌓아서 model size를 키웠다.
- 양질의 data 학습
- 학습 data를 수집할 때 여러 답글중 좋아요가 많은 data
- 답글에 링크가 포함되어있을 때 링크내의 문서를 학습에 사용한다.
- 양질의 data 학습
-
Zero-shot setting에서의 downstream
-
모델이 훈련 과정에서 특정 요약에 대한 데이터를 받지 않았지만, 주어진 문맥을 이용하여 새로운 지문을 요약하는 작업을 수행합니다.
-
주어진 지문 구성:
- Zero-shot setting에서 주어진 지문은 요약이 필요한 대상 지문입니다. 이 지문은 일반적으로 길고 복잡한 내용을 포함합니다.
-
TL;DR 추가:
- 주어진 지문의 끝 부분에는 “TL;DR”이라는 표시가 있습니다. “TL;DR”은 “Too Long; Didn’t Read”의 약어로, 이 부분이 요약을 표현하는 부분입니다.
-
Zero-shot 요약 작업:
- 모델은 특별한 요약 훈련을 받지 않았지만, 주어진 지문과 “TL;DR” 이후의 내용을 이용하여 요약을 수행합니다.
-
-
GPT - 3
- transfomer model에 self-attention block을 사용한 decoder를 그대로 계승해왔다.
- 하지만 학습 data와 layer를 훨씬 더 많이 쌓음으로 해서 발전 시켰다.
- Prompt (프롬프트):
- GPT-3에서 프롬프트는 모델에게 주어지는 초기 문장 또는 질문을 의미한다. 이는 모델이 수행할 작업을 정의하거나 지시하는 역할을 한다. GPT-3는 주어진 프롬프트를 기반으로 문맥을 이해하고 응답을 생성한다.
- Zero-shot (제로샷):
- GPT-3의 Zero-shot 설정에서는 특정 작업에 대한 훈련 데이터 없이도 모델은 주어진 문제에 대한 답을 예측하려고 한다. 이는 모델이 자연어 이해 및 생성 능력을 활용하여 새로운 작업에 대응하는 데 사용된다.
- One-shot (원샷):
- One-shot 설정에서는 GPT-3가 특정 작업에 대한 단 하나의 예시를 볼 수 있다. 이 예시는 모델에게 작업을 이해하고 실행하는 데 도움이 되는 추가적인 정보를 제공한다.
- Few-shot (퓨샷):
- Few-shot 설정에서는 GPT-3가 특정 작업에 대한 몇 가지 예시를 볼 수 있다. 이는 모델이 해당 작업에 더 잘 적응하고 일반적인 지식을 유지하면서도 특정 작업에 대해 더 특화되게 학습되도록 한다.
댓글남기기