[Trend Color Matching Project] 3. KNN을 이용한 하의 색상 예측 모델
[공지사항] [YOLOv5를 활용하여 남성 상하의를 감지하고, Kmeans와 KNN을 활용하여 트렌드에 맞는 패션 컬러를 자동으로 예측하는 개인 프로젝트입니다.] 👉🏻깃허브 바로가기
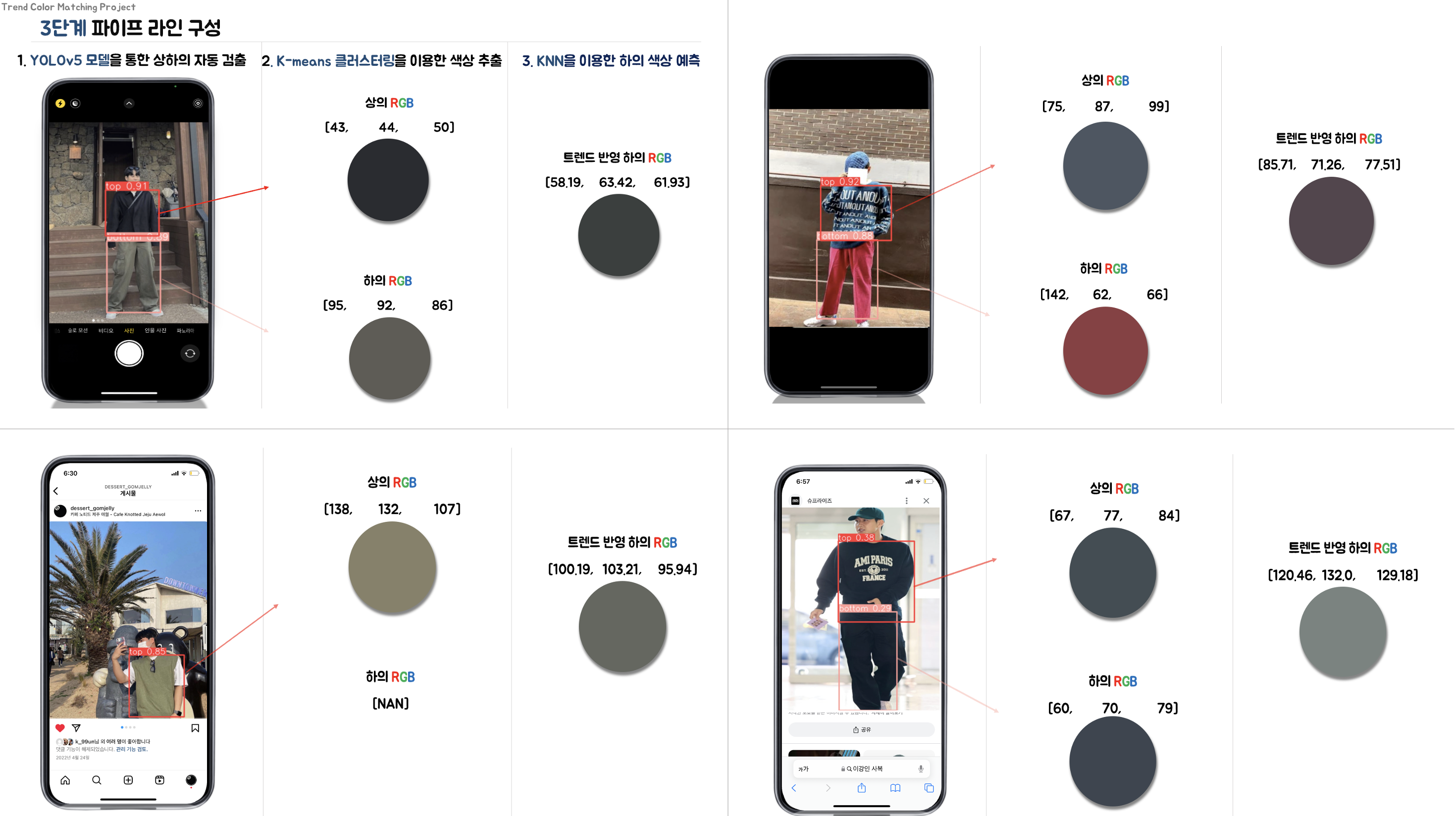
트렌드 기반 패션 컬러 매칭 프로젝트 3편
트렌드 기반 패션 컬러 매칭 프로젝트
- 3 . KNN을 이용한 하의 색상 예측 모델
- 👉🏻코드 바로가기
트렌드 기반 패션 컬러 매칭 프로젝트 1편에서 설계했던 파이프라인에서 하의 색상 예측 모델 을 만들 차례이다.

트렌드 기반 패션 컬러 매칭 프로젝트 2편의 결과로 나온 3개의 csv 파일을 불러와 학습에 사용하도록 한다.

데이터 전처리
색상 추출의 결과를 불러오면 Label 과 RGB 형태로 나온다. 학습에 걸맞는 형태로 데이터 프레임을 전처리 해야할 필요성을 느꼈다.
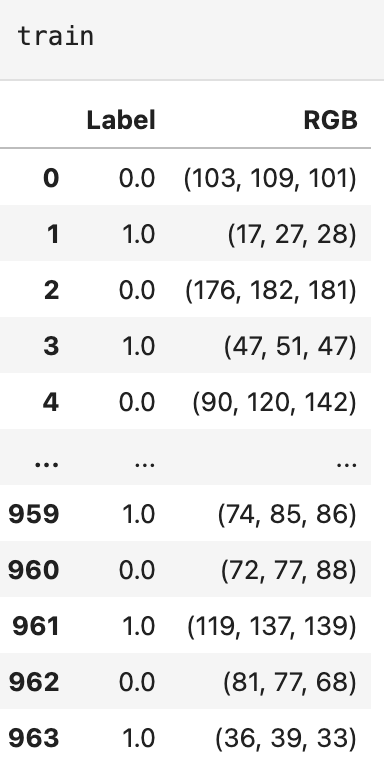
우리의 프로젝트의 목표 달성하기 위해서는 상의 RGB 값에 따른 하의 RGB 값을 학습 시켜야한다. 그래야 새로운 상의 RGB 값을 넣었을 때 트렌드에 기반한 하의 RGB 값이 나오기 때문이다.
데이터 전처리는 3단계로 구성했다.
- 상의 또는 하의 데이터가 없는 경우가 있기 때문에 Label 이 0,1이 연속해서 나오지 않을 경우를 삭제한다.
- Label 열을 삭제하고 TOP_RGB, BOTTOM_RGB 열로 재배치한다.
- train, test, valid 데이터프레임을 합친다.
다음은 코드 설명이다.
[상의 또는 하의 데이터가 없는 경우]
shift(-1) 함수를 사용하여 현재 행과 다음 행의 값을 비교했다.

[TOP_RGB, BOTTOM_RGB]
Label열을 삭제 하고 재배치 하기 위하여 Label로 데이터 프레임을 나누고 합쳐줬다.


[train, test, valid 데이터프레임 합치기]
concat을 이용하여 합쳐 줬고 학습을 시키기 위한 최종 데이터 프레임은 다음과 같다.

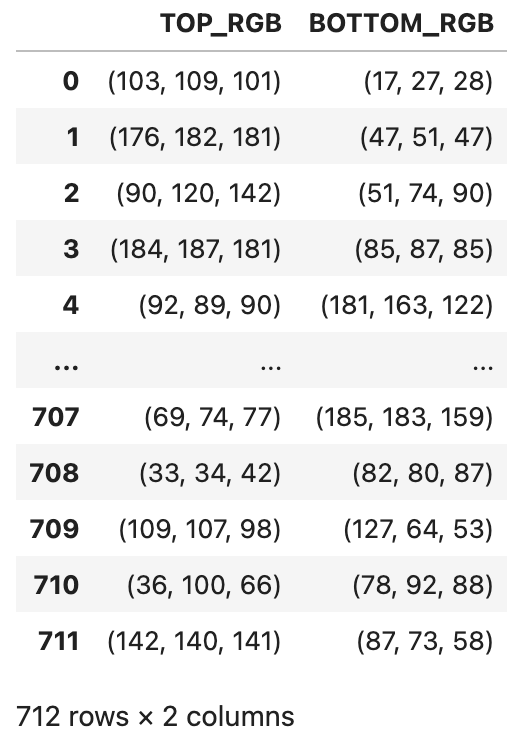
학습 데이터 만들기
주어진 2019년 패션 데이터의 색상 추출 데이터를 학습에 맞는 데이터로 만들어 줘야 한다.
먼저 RGB 값은 0부터 255까지의 값을 갖고 있기 때문에 학습을 위해 0에서 1사이의 실수 값으로 정규화 했다.
[정규화]
정규화를 한 값을 eval 함수를 사용하여 문자열 형태의 RGB 값을 파이썬 리스트로 변환해준다.

[X, Y 설정]
상의인 TOP_RGB를 X, 예측해야하는 하의 BOTTOM_RGB를 y값으로 설정한다.
분리할때는 국룰 처럼 사용하는 size = 20% , random_state = 42 로 설정했다.

모델 학습
모델 학습을 하기 위하여 정말 많이 고민했다.
R G B 값으로 R G B 값을 예측 해야 하며, R G B 채널은 각 채널에 영향을 미쳐야 한다는 조건이 매우 까다로웠다.
MLP
단순한 회귀 모델로는 예측 하기 어려울거 같아 MLP 모델을 사용해 보기로 했다.
다층퍼셉트론에 대한 개념은 내 블로그에 포스팅 되어있다. MLP 모델 설명 바로가기
코드는 다음과 같다.
# 모델 선택 및 훈련 (MLP with Dropout and legacy Adam optimizer)
model = Sequential()
model.add(Dense(units=64, activation='relu', input_dim=3))
model.add(Dropout(0.1))
model.add(Dense(units=32, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(units=3))
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='mean_squared_error')
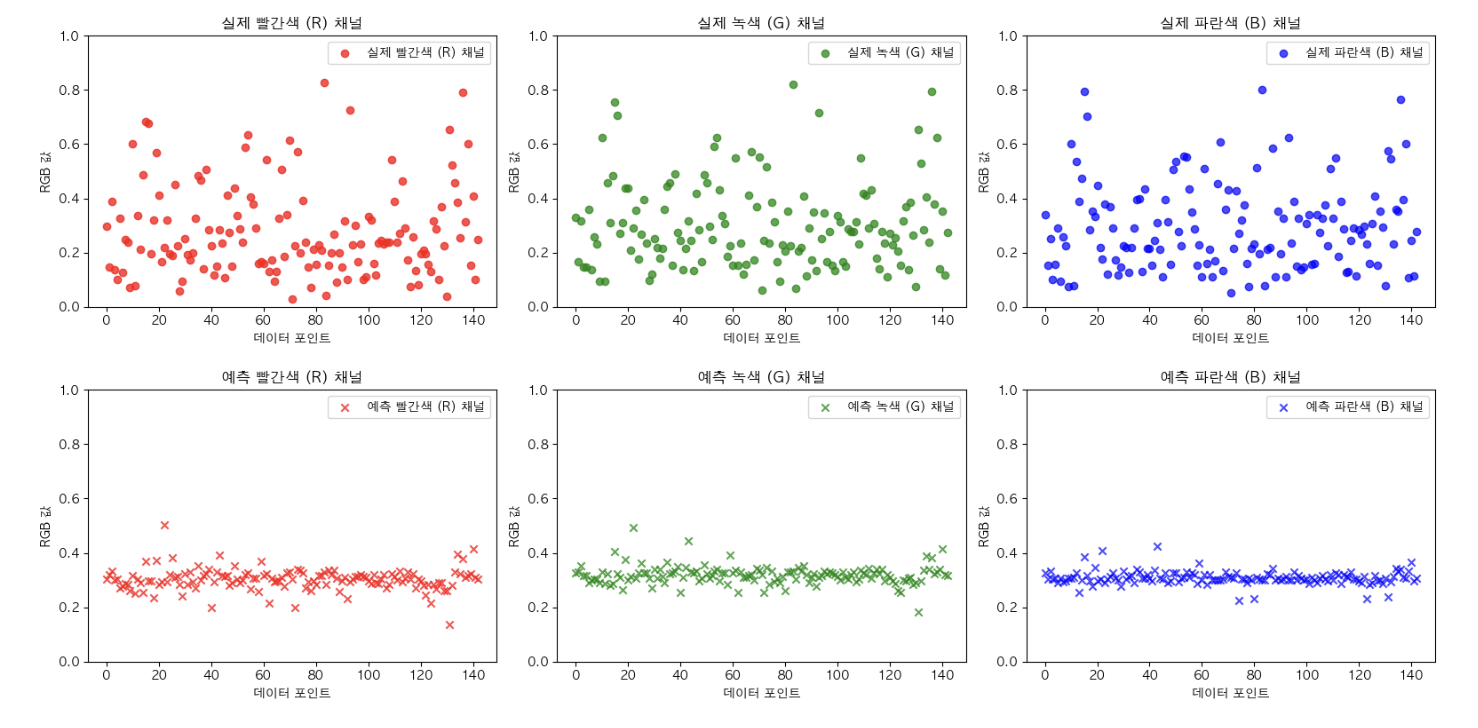
Mean Squared Error: 0.0247 이 나와 예측이 잘 되었다고 생각했다.
하지만 R G B 각 채널 마다 데이터 포인트에 따른 값을 비교해보았다.
그 결과… ^^ ..^^
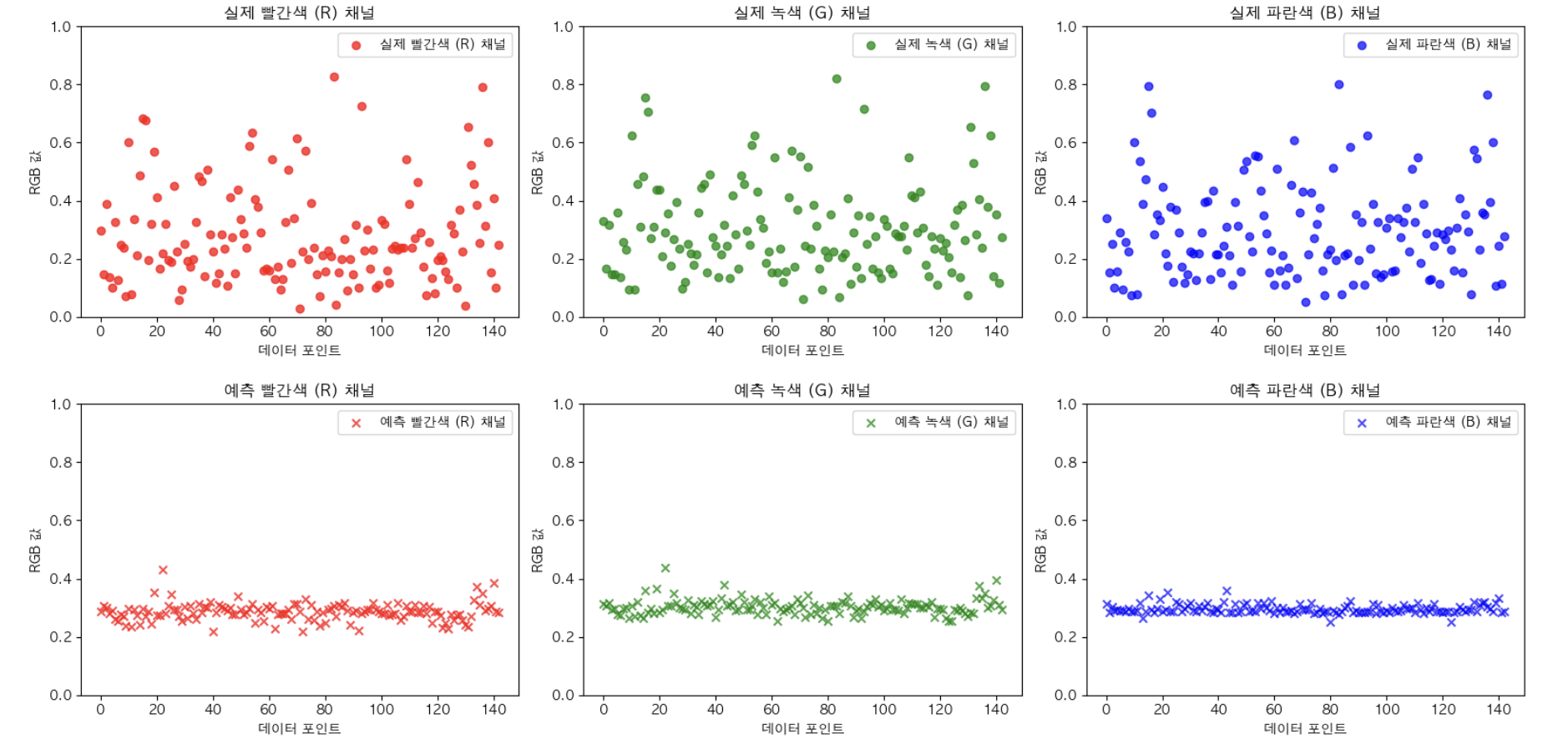
아마도 R G B 값으로 R G B 값을 예측 해야한다는 조건 때문에 MLP보다도 단순한 회귀 모델이 필요하다고 느꼈다.
그리고 사실 이쯤에서 데이터가 부족하다고 느껴 데이터 300장을 더 추가했다.^^ 하지만 역시나 실패
다른 모델을 찾아보자.
LinearRegression
제일 단순한 모델부터 다시 시작해보기로 했다.
# 모델 훈련
model = LinearRegression()
model.fit(X_train, y_train)
# 모델 예측
y_pred = model.predict(X_test)
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
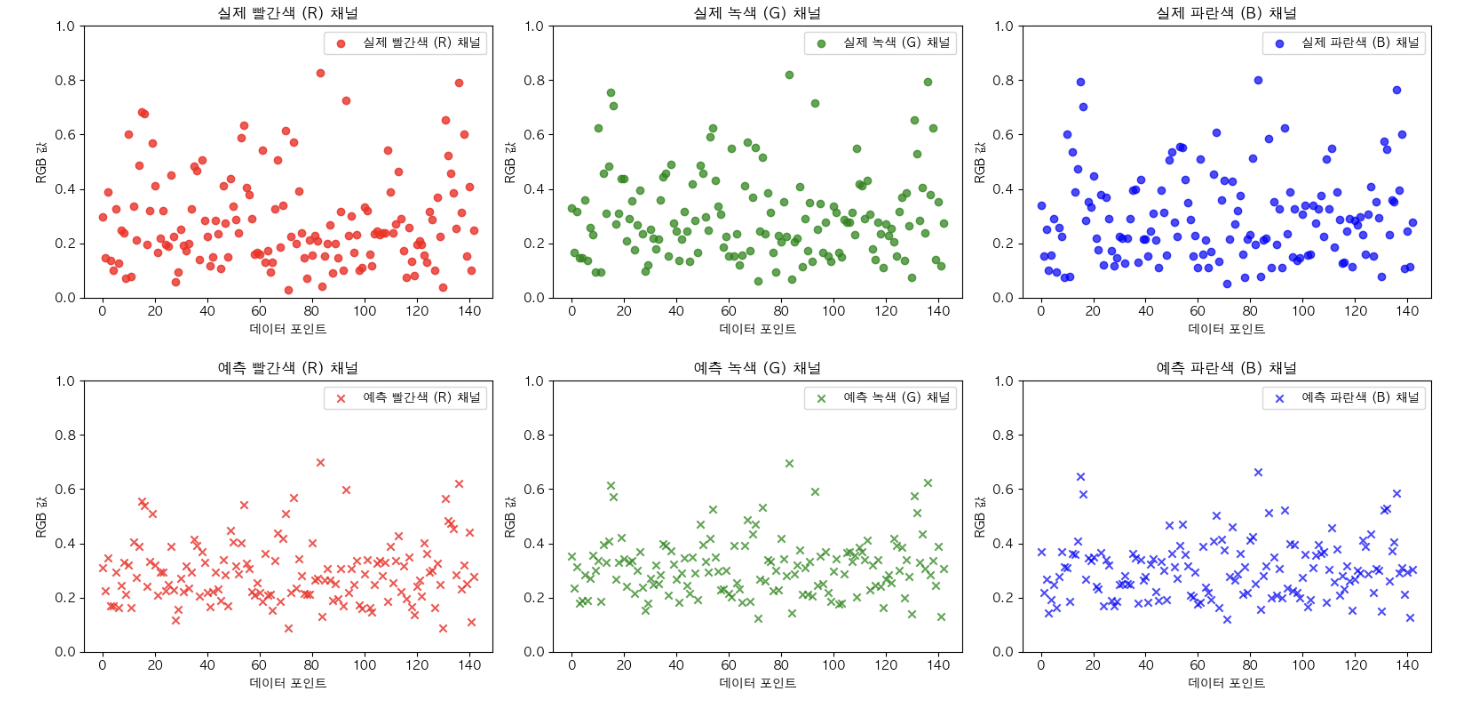
Mean Squared Error는 0.0255가 나왔 지만 여전히 예측이 잘 되지 않고 있다.
하지만 MLP보다는 살짝이라도 좋아진 모습였기 떄문에 희망을 잃지 않았다.
RandomForest
랜덤 포레스트 모델은 데이터의 노이즈를 줄이고 안정적인 예측을 제공하며, 다양한 특성을 고려함으로써 일반화 성능을 향상시킬 수 있다.
예측이 생각보다 잘 되어서 하이퍼 파라미터를 조정해 줬다.
코드는 다음과 같다.
# RandomForestRegressor 모델 초기화
rf_model = RandomForestRegressor(random_state=42)
# 탐색할 하이퍼파라미터 그리드 정의
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# GridSearchCV를 사용하여 최적의 하이퍼파라미터 찾기
grid_search = GridSearchCV(rf_model, param_grid, cv=3, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
# 최적의 모델 얻기
best_rf_model = grid_search.best_estimator_
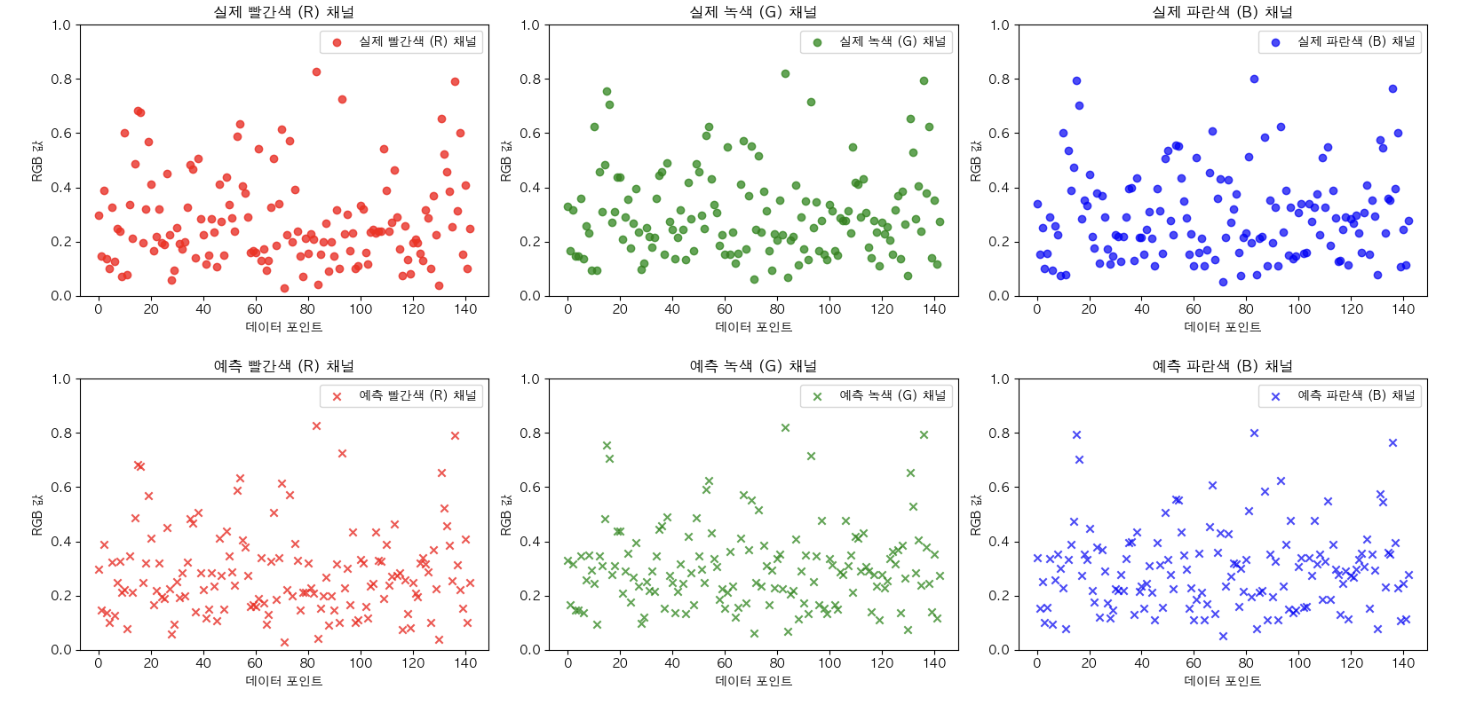
Mean Squared Error는 0.0089로 지금까지의 모델보다 훨씬 더 좋다. 예측 또한 매우 좋아졌지만 뭔가… 아쉽다.
K-최근접 이웃 (KNN) 알고리즘을 통한 RGB 예측 성공!!!
드디어 KNN 알고리즘으로 만족할만한 결과를 냈다.
그리드 서치를 통해서 하이퍼 파리미터를 조정 해줬고, [ n_neighbors = 10, p = 1, weights = distance] 로 그리드 서치가 완료 되었다.
# 탐색할 하이퍼파라미터 그리드 정의
param_grid = {
'n_neighbors': [3, 5, 7, 10], # 원하는 이웃 수로 변경 가능
'p': [1, 2], # 1: 맨해튼 거리, 2: 유클리디안 거리
'weights': ['uniform', 'distance'] # 균일한 가중치 또는 거리에 따른 가중치
}
# KNN 모델 초기화
knn_model_tuned = KNeighborsRegressor()
# GridSearchCV를 사용하여 최적의 하이퍼파라미터 찾기
grid_search = GridSearchCV(knn_model_tuned, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
# 최적의 모델 얻기
best_knn_model = grid_search.best_estimator_
모델 평가 지표는 다음과 같다.
| 평가지표 | 설명 | 값 |
|---|---|---|
| MSE (Mean Squared Error) | 모델이 테스트 데이터에서의 예측이 정확함을 나타내는 지표. 작은 값일수록 좋음. 튜닝된 KNN 모델은 MSE가 0.0061로 매우 낮게 나타남. | 0.0061 |
| R-squared Score | 예측값이 실제 값의 변동을 얼마나 잘 설명하는지를 나타내는 지표. 1에 가까울수록 좋음. 모델의 R-squared Score는 0.76로 전체 변동 중 76%를 설명함. | 0.7646 |
| MAE (Mean Absolute Error) | 예측값과 실제 값 간의 평균 절대 오차. 작을수록 좋음. 모델의 MAE는 0.0263으로 평균적으로 0.0263의 오차를 갖음. | 0.0262 |
내가 생각했을 때에 KNN의 성능이 제일 좋았던 이유는 다음과 같다.
1. 색상 유사성을 고려한 예측:
- KNN은 새로운 데이터 포인트를 예측할 때, 주변 이웃들의 정보를 활용한다. RGB 예측에서는 유사한 색상을 가진 이웃들이 더 큰 영향을 미친다.
2. 가중 평균 활용:
- ‘distance’ 옵션을 사용하여 가까운 이웃에 더 큰 가중치를 부여한다. 이는 RGB 값이 가까운 이웃이 예측에 미치는 영향을 강화시킨다.
3. 맨해튼 거리 측정:
- 맨해튼 거리는 RGB 값 간의 색상 차이를 정확하게 측정하는 데 도움을 준다. 따라서 모델은 색상 유사성을 더 정확하게 파악하고 예측한다.
👉🏻전체 코드 바로가기 전체 코드는 깃허브에서 참고 하면 된다.
댓글남기기